
- diciembre 12, 2024
- 0 Comments
- By Laura García Bustos
¿Qué es Nagios?
Nagios es un sistema de monitorización ampliamente utilizado, de código abierto, que se encarga de vigilar los equipos (hardware) y servicios (software) que se especifiquen, además de alertar cuando el comportamiento de estos no sea el deseado.
Entre sus características principales figuran la monitorización de servicios de red (SMTP, POP3, HTTP, SNMP…), la monitorización de los recursos de sistemas hardware (carga del procesador, uso de los discos, memoria, estado de los puertos…), independencia de sistemas operativos, posibilidad de monitorización remota mediante túneles SSL cifrados o SSH, y la posibilidad de programar plugins específicos para nuevos sistemas.
Necesidad de los sistemas de monitorización
Quizá sea conveniente hablar en primer lugar de las ventajas de los sistemas de monitorización en un sentido general, y no se nos ocurre mejor forma de hacerlo que explicar cual es el papel que desempeñan.
Supongamos que somos responsables del funcionamiento de unas aplicaciones que se ejecutan en una serie de servidores. Podemos comprobar que la aplicación funciona conectándonos a ella, si se trata de una aplicación web, podemos intentar abrir la página principal, la landing. Si la aplicación depende de una base de datos podemos hacer conexiones con cualquier cliente. Otros elementos que deberíamos comprobar son que los discos y volúmenes tienen espacio suficiente para seguir guardando los datos que se van generando, que la memoria RAM no llega al límite en el que empieza a hacer swaping, es decir, a volcar información al disco para utilizarlo de memoria virtual, y que la CPU tiene margen para seguir aceptando la carga de trabajo que genera la actividad de las aplicaciones. En servidores Linux utilizaríamos comandos como top, df, dh, etc.
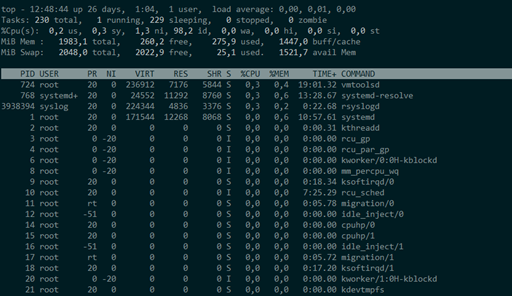
En servidores Windows abriríamos el monitor de recursos:

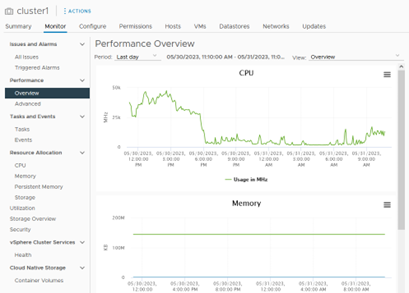
En otros sistemas, como por ejemplo los de virtualización (VMWare, Proxmox, etc.) podemos consultar sus herramientas propias:
Si queremos ser rigurosos y no queremos pasar por alto ninguna de las tareas, las podemos tener registradas en una tabla como la del ejemplo, en la que anotaríamos lo que hacemos y consultaríamos las tareas que quedan por hacer:
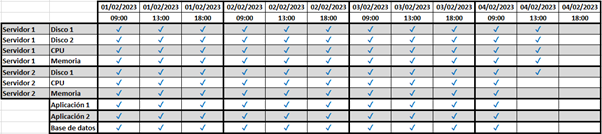
La podríamos mejorar registrando los valores de cada métrica, y así sabríamos que a cierta hora de cierto día la web y la base de datos estaban funcionando, la CPU estaba al 60%, la RAM al 80% y el disco tenía un 35% de espacio ocupado.
Con responsabilidad y compromiso al principio haríamos un seguimiento exhaustivo con comprobaciones cada hora (si no tenemos nada mejor que hacer), pero antes de que acabase el día espaciaríamos más los chequeos, quizá decidiésemos hacerlo a primera hora, media mañana, medio día, media tarde y final de la jornada, luego suprimiríamos los de media mañana y media tarde, luego el de mediodía, y finalmente, de una manera tácita, decidiríamos que hemos diseñado la infraestructura de una forma tan robusta que nos podemos permitir el lujo de chequearla de vez en cuando.
Los sistemas de monitorización se encargan de automatizar las verificaciones que manualmente podemos hacer de una forma más eficiente. Podemos programarlos para que hagan chequeos con una frecuencia que es imposible hacer manualmente, por ejemplo, cada minuto, cada hora, o cada día; y que envíen una notificación cuando no haya respuesta, o cuando la respuesta indique que la métrica consultada ha traspasado el umbral que hayamos marcado, por ejemplo, cuando la CPU de un servidor pase del 90%. De esta forma sólo tenemos que revisar los sistemas cuando hay un problema, en lugar de hacerlo regularmente por si lo hubiese.
Ventajas de la monitorización con Nagios
Analicemos a continuación las características y ventajas que ofrece Nagios como servicio de monitorización:
1. Flexibilidad para configurar periodos de chequeo:
Como ya hemos mencionado anteriormente, un sistema de monitorización permite chequeos constantes a intervalos de tiempos regulares. En la imagen podemos ver una configuración para hacer chequeos cada minuto, durante todo el día y durante todos los días de la semana. Además, la notificación es un concepto independiente al chequeo. Si no fuese así, recibiríamos un correo cada minuto mientras nos se resolviese la incidencia, pero con la configuración que vemos en la imagen sólo se notifica cada 3 horas mientras no se resuelva el problema. También podríamos limitar las notificaciones a determinados días u horas del día, y podemos especificar los casos en los que se debe notificar, que en este se ejemplo son Warning, Unreachable, Critical y Recover, es decir, cuando se resuelven los estados de error anteriores.
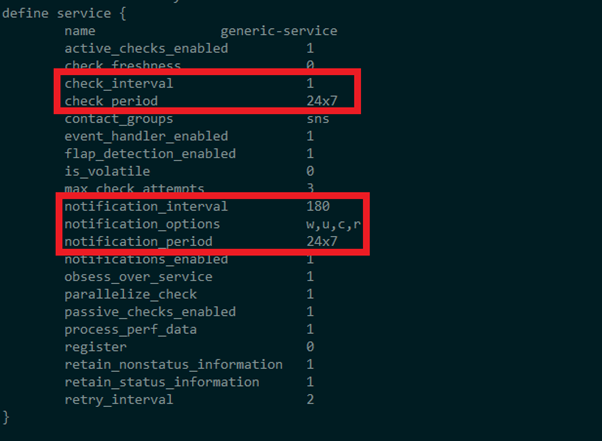
Se puede ver que estas opciones quedan dentro de la definición de un servicio. Podemos definir servicios adicionales con otras opciones diferentes para aplicarlos a diferentes objetivos en función de la criticidad de uno de ellos. Aprovechemos para recordar que un exceso de notificaciones no tiene por qué ser lo más adecuado. Demasiadas notificaciones pueden distraernos de otras tareas o incluso hacer que las ignoremos, llevándonos a un escenario similar al que teníamos cuando hacíamos las verificaciones de forma manual.
2. Flexibilidad para configurar notificaciones
También podemos personalizar las notificaciones editando el correspondiente comando. Vemos 2 ejemplos en la imagen que, pese a tener la definición por defecto, gracias al uso de las variables de Nagios se pueden aplicar a distintos objetivos sin que en las notificaciones que recibamos falte información para identificar el origen del problema.

Pero, aun así, podemos añadir información en la definición si lo creemos necesario.
3. Panel centralizado
Nagios ofrece una web a la que se accede con usuario y contraseña, dentro de la cual tenemos varios paneles desde los cuales tenemos una visión general del estado de todo el entorno. En la imagen vemos el de Host Groups, en los que aparecen los hosts monitorizados agrupados según el plan que hayamos configurado:

En este caso tenemos 15 hosts agrupados en 3 grupos. En el último grupo hay un host con un warning, haciendo clic en él podemos ver cuál de los servicios monitorizados en este host es el que tiene un problema.
Casi todos estos equipos son servidores Windows y Linux, pero también hay algún equipo de red. Son los que tienen la leyenda no matching services porque no estamos monitorizando componentes concretos. Sólo por estar añadidos a la configuración Nagios comprueba que estén funcionando, enviándoles un PING periódico. Si no respondiesen al PING pasarían del estado UP a DOWN y recibiríamos la correspondiente notificación.
4. Logs centralizados
Otro panel resume el historial de alertas. Lo podemos consultar si no hubiésemos recibidos las notificaciones o ya las hubiésemos eliminado. Pero incluso si contamos con ellas, en este panel es mucho más fácil comprobar las horas a las que se han dado los eventos.

5. Estadísticas e informes
De forma similar a como obtenemos los logs podemos sacar otros informes y estadísticas. Mostramos en primer lugar la posibilidad de filtrar:
Y el resultado que se obtiene:
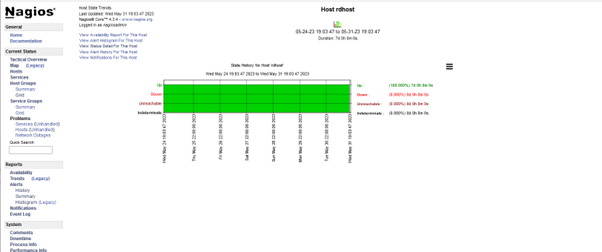
6. Integraciones
Gracias al extendido uso de Nagios, podemos encontrar múltiples aplicaciones que se pueden integrar para extender su funcionamiento. Ponemos 3 ejemplos:- SLACK: Aplicación de comunicación en tiempo real. Integrándose con Nagios, este puede notificar a los responsables de TI que estén suscritos al canal. Aquí dejamos el link a la documentación.
- JIRA: Las alarmas lanzadas por Nagios automáticamente crean una incidencia en esta herramienta de gestión de proyectos y seguimiento de proyectos. Aquí dejamos el link a la documentación.
- MySQL: Para la monitorización de esta base de datos no es necesaria ninguna extensión. La instalación estándar cuenta con un plugin que permite comprobar la conexión, el tiempo que necesita la base de datos para devolver una consulta, etc.
7. Escalabilidad
Nagios soporta una arquitectura distribuida para ajustarse a entornos extensos. Podemos instalar varios servidores y dedicar cada uno a recursos específicos, y agregar servidores satélites conocidos como Nagios Remote Data Processor (NDRP). A través de este protocolo las distintas instancias de Nagios se comunican entre sí y envían los resultados de los chequeos al servidor de Nagios.8. Automatización de tareas
Es posible programar la ejecución de tareas en respuesta a alarmas de Nagios. Las tareas pueden ir desde el reinicio de un servicio a la ejecución de un script que solucione el problema que ha dado lugar al evento. Así damos un paso más en la reducción de la necesidad de la intervención manual.9. Cumplimiento de SLAs
En línea con la capacidad de automatización de la que venimos hablando desde el principio, no creemos que haga fata explicar cómo Nagios es una herramienta que nos ayuda cuando tenemos unos niveles de servicio acordados que cumplir. No debemos ver Nagios como una herramienta para solucionar incidencias, si no una herramienta para identificarlas de forma temprana y prevenirlas. Si somos capaces de configurar los umbrales de alerta y los intervalos de verificación y los periodos de notificación de forma adecuada, seremos capaces de anticiparnos a cualquier avería.10. Precio
Que el coste económico sea nulo en términos de licenciamiento es otra ventaja porque todo lo que hemos comentado lo tenemos con la versión gratuita, pero si queremos probar la versión de pago, NAGIOS XI, estas son sus principales ventajas:- Una interfaz gráfica para configurar la aplicación de una forma más intuitiva. Reconozcamos que editar archivos de configuración no es algo sencillo, y mucho menos si no hemos trabajado anteriormente con una ventana de comandos.
- Un soporte técnico para la resolución de problemas, consultas, actualizaciones y corrección de errores. En la versión gratuita el principal soporte es una extensa comunidad de usuarios, a la cual también podríamos, la cual no deja de ser otra ventaja de las que venimos comentando.




