- marzo 3, 2026
- 0 Comments
- By Elena

Miguel Ángel Tomé
Introducción
En 2026, los entornos TI serán más complejos que nunca. Microservicios distribuidos, arquitecturas multinube, contenedores efímeros y aplicaciones híbridas generan volúmenes masivos de datos operativos. Gestionar estos datos manualmente es inviable y aumenta el riesgo de errores, interrupciones y pérdida de visibilidad, afectando la continuidad de negocio y la experiencia de usuario.
AIOps (Artificial Intelligence for IT Operations) se consolida como un paradigma que combina inteligencia artificial, machine learning, analítica avanzada y automatización para transformar la operación de TI. Su alcance va desde la detección automática de anomalías, hasta la resolución predictiva de incidentes y la optimización de recursos en tiempo real, habilitando un modelo operativo proactivo, resiliente y escalable.
Este artículo aborda AIOps desde un enfoque técnico y profesional, con énfasis en:
- Principios fundamentales y conceptos clave.
- Arquitectura y componentes tecnológicos avanzados.
- Algoritmos de machine learning y técnicas de IA aplicadas a TI.
- Casos de uso operativos y estratégicos.
- Métricas de eficiencia, KPIs críticos y dashboards.
- Retos de implementación y mejores prácticas.
- Integración con DevOps y DevSecOps.
Esquema operativo de AIOps: del dato a la acción automatizada
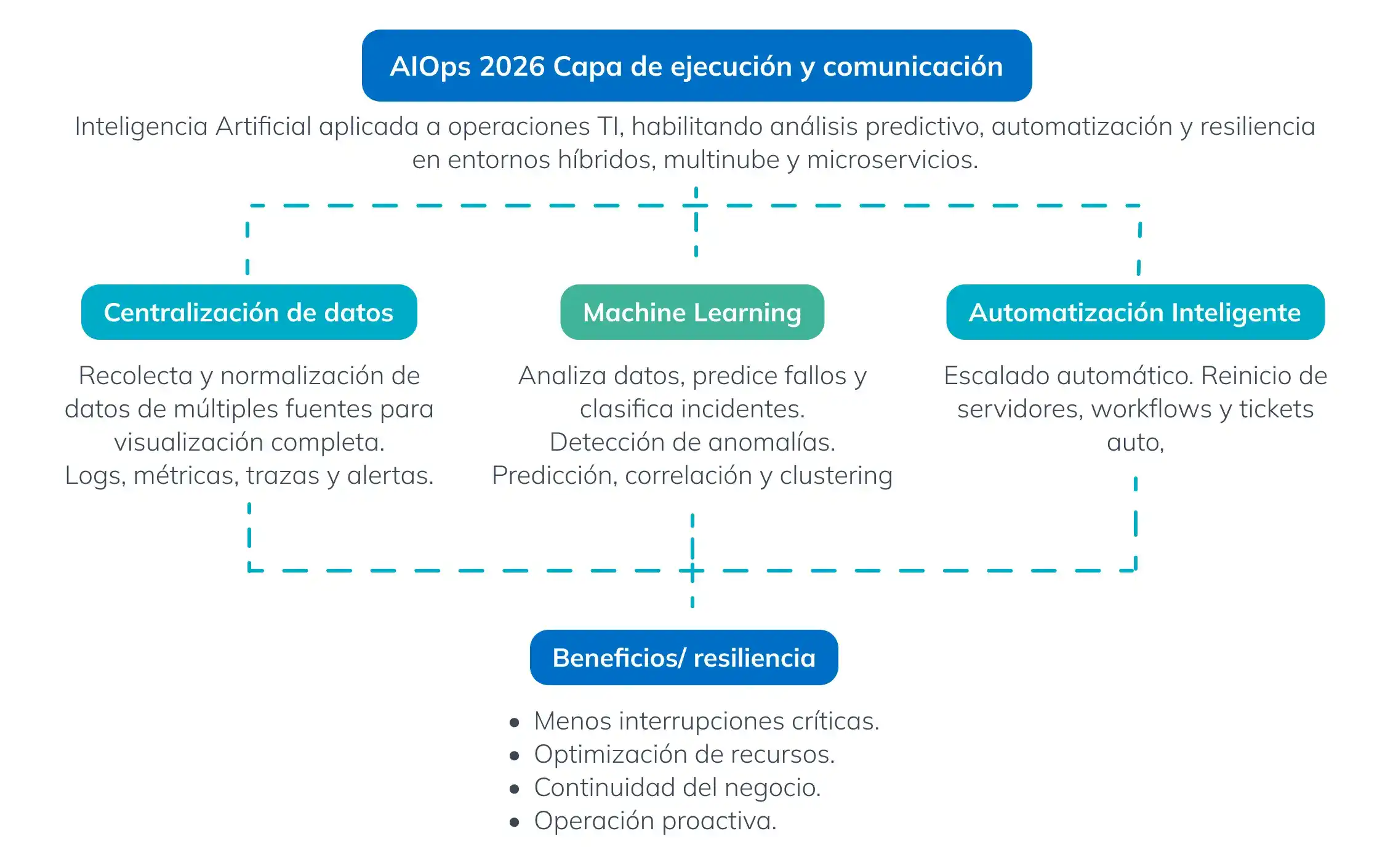
Principios Fundamentales de AIOps
1. Centralización y correlación de datos
El primer principio de AIOps es la centralización de datos operativos de múltiples fuentes para identificar patrones, relaciones y dependencias complejas:
- Logs de aplicaciones, contenedores y sistemas operativos: eventos, errores y trazabilidad.
- Métricas de rendimiento y disponibilidad: CPU, memoria, latencia, throughput y errores de red.
- Eventos de infraestructura y redes: switches, routers, firewalls y balanceadores de carga.
- Trazas de microservicios y transacciones distribuidas: dependencias de servicios y flujos de negocio.
- Alertas de herramientas de monitoreo tradicionales: Nagios, Prometheus, Datadog, Zabbix.
La correlación de datos permite identificar la causa raíz de incidentes, reducir alertas redundantes y aumentar la eficiencia operacional.
2. Machine Learning y analítica avanzada
El corazón de AIOps es el uso de modelos de ML y técnicas de IA para análisis predictivo y detección proactiva de problemas:
- Detección de anomalías: identifica desviaciones en métricas de rendimiento, uso de CPU, memoria y latencia de servicios.
- Clustering y correlación de eventos: agrupa eventos similares para reducir ruido y priorizar alertas críticas.
- Predicción de fallos: anticipa degradaciones de servicio y permite ajustes proactivos de recursos.
- Clasificación automática de incidentes: asigna prioridad y categoría de manera automática, optimizando los flujos de trabajo del equipo de operaciones.
Técnicas ML empleadas en AIOps:
- RNN / LSTM: utilizadas para la predicción de degradación progresiva y la detección de anomalías en series temporales, permitiendo anticipar fallos a partir de patrones históricos de comportamiento.
- Random Forest / Gradient Boosting: aplicados a la clasificación automática de incidentes, facilitando la identificación de su tipología, origen probable y nivel de criticidad.
- K-Means / DBSCAN: empleados para el clustering de eventos y la correlación de alertas, permitiendo agrupar comportamientos similares e identificar patrones operativos recurrentes o incidentes relacionados.
- ARIMA / Prophet: utilizados en la predicción de capacidad y el análisis de tendencias de consumo, facilitando la planificación de recursos y la optimización de la infraestructura.
- Autoencoders: orientados a la detección de desviaciones inusuales en métricas operativas, identificando comportamientos anómalos que no siguen los patrones normales del sistema.
- Grafos probabilísticos: utilizados para el modelado de dependencias entre servicios, sistemas y eventos, permitiendo analizar el impacto de fallos y entender relaciones complejas dentro de arquitecturas distribuidas
3. Automatización inteligente y resiliencia
Más allá de la detección, AIOps habilita automatización avanzada de respuesta:
- Escalado automático de infraestructura: horizontal o vertical según predicciones de carga.
- Reinicio automático de servicios o contenedores afectados.
- Ejecución de scripts y workflows predefinidos basados en triggers de ML.
- Notificación automática y generación de tickets con diagnóstico y acciones sugeridas.
Esto reduce significativamente el MTTR (Mean Time to Resolve) y aumenta la resiliencia del sistema ante fallos.
Arquitectura y Componentes de AIOps
Una plataforma AIOps avanzada incluye:
- Ingesta y normalización de datos: centraliza logs, métricas, trazas y eventos en formatos estandarizados.
- Almacenamiento y análisis de Big Data: bases de datos escalables y pipelines de procesamiento en tiempo real.
- Motor de Machine Learning: aplica modelos predictivos, de clustering y correlación para detectar anomalías y patrones.
- Motor de automatización y orquestación: ejecuta acciones correctivas, ajustes de capacidad y workflows de respuesta a incidentes.
- Visualización y dashboards inteligentes: muestran alertas priorizadas, KPIs operativos y métricas predictivas en tiempo real.
- Integración con ITSM, DevOps y herramientas de seguridad: alimenta sistemas de ticketing, pipelines CI/CD y plataformas DevSecOps.
Algoritmos y Técnicas de Machine Learning Aplicadas
Función |
Algoritmos/Técnicas |
Beneficios |
|---|---|---|
Detección de anomalías |
Isolation Forest, One-Class SVM, Autoencoders |
Identificación temprana de desviaciones |
Predicción de capacidad y fallos |
LSTM, ARIMA, Prophet |
Ajuste proactivo de recursos |
Correlación de eventos |
Grafos probabilísiticos, Clustering jerárquico |
Reducción de ruido y priorización de alertas |
Automatización híbirda |
Reglas + ML adaptativo |
Precisión en acciones correctivas automáticas |
Optimización de pipelines CI/CD |
ML para identificación de riesgos y despliegues |
Mejora de seguridad y reducción de incidentes de producción |
Casos de Uso Estratégicos y Operativos
- Prevención de interrupciones críticas: correlación de eventos y predicción de fallos para garantizar alta disponibilidad.
- Optimización de recursos multinube: ajuste automático de capacidad basado en patrones históricos y predicción de demanda.
- Automatización de workflows operativos: reinicio de servicios, escalado de contenedores y mitigación de incidentes de seguridad.
- Detección de problemas de rendimiento: monitoreo de microservicios y aplicaciones críticas en tiempo real.
- Cumplimiento y auditoría automatizada: trazabilidad completa de incidentes, acciones correctivas y reporting regulatorio.
Métricas y KPIs Críticos en AIOps
- MTTD (Mean Time to Detect): tiempo promedio para identificar incidentes.
- MTTR (Mean Time to Resolve): tiempo promedio para resolver incidentes.
- Reducción de alertas redundantes: ruido operativo eliminado.
- Disponibilidad y SLA: impacto directo en la continuidad de servicios.
- Precisión de predicciones y recomendaciones: efectividad de modelos ML y automatización.
- Adopción de acción automatizada: porcentaje de incidentes resueltos sin intervención manual.
Integración con DevOps y DevSecOps
AIOps potencia las operaciones DevOps y DevSecOps mediante:
- Integración con pipelines CI/CD para detección de riesgos en tiempo real.
- Correlación de cambios de código con incidentes operativos y alertas.
- Automatización de pruebas de seguridad y despliegues seguros.
- Monitoreo continuo de aplicaciones y contenedores durante todo el ciclo de vida del software.
Retos y Mejores Prácticas
Retos
- Integración de datos heterogéneos y múltiples formatos.
- Calidad y limpieza de datos para entrenamiento de modelos ML.
- Alineación organizativa entre operaciones, desarrollo y seguridad.
- Gestión de entornos híbridos, multinube y contenedores efímeros.
- Escalabilidad de plataformas ML para correlación de eventos en tiempo real.
Mejores Prácticas
- Definir métricas y objetivos claros antes de implementar AIOps.
- Adoptar un enfoque incremental, empezando con casos de uso concretos.
- Monitorear y ajustar continuamente los modelos ML.
- Garantizar visibilidad y trazabilidad en todos los procesos automatizados.
- Integrar AIOps con ITSM, DevOps y herramientas de seguridad para un enfoque unificado.
Impacto Estratégico de AIOps
- Optimización de eficiencia operativa: reducción de esfuerzo manual y tiempo de resolución de incidentes.
- Resiliencia mejorada: prevención proactiva de interrupciones críticas.
- Toma de decisiones basada en datos: correlación de eventos, analítica predictiva y priorización de incidentes.
- Continuidad de negocio y cumplimiento: trazabilidad y reporting automático de acciones.
- Transformación digital: facilita operaciones automatizadas en entornos híbridos y multinube, mejorando SLA y reduciendo riesgos.
Conclusión
AIOps representa una transformación integral en la operación TI, convirtiendo entornos complejos en sistemas proactivos, predictivos y altamente automatizados. Su implementación permite reducir errores humanos, optimizar recursos, mejorar eficiencia y asegurar continuidad de negocio.
El éxito de AIOps requiere:
- Planificación estratégica y alineación organizativa.
- Integración de datos de calidad desde múltiples fuentes.
- Modelos de ML bien entrenados y monitoreados continuamente.
- Automatización avanzada de workflows y respuesta a incidentes.
El resultado es una operación TI más eficiente, resiliente y preparada para la era digital, capaz de enfrentar entornos complejos, dinámicos y distribuidos con seguridad, eficiencia y visibilidad completa.