- noviembre 22, 2022
- 0 Comments
- By Laura García Bustos

Laura García | Digital Marketing & Communication
En la web encontramos multitud de páginas, blogs y foros en los que se habla y discute sobre lo que son los microservicios. Sin ir más lejos, en Wikipedia podemos leer la siguiente definición:
La arquitectura de microservicios es una aproximación al desarrollo de software que consiste en construir una aplicación como un conjunto de pequeños servicios” y también que “se suele considerar la arquitectura de microservicios como una forma específica de realizar una arquitectura orientada a servicios.
Y este es uno de los puntos sobre los que se discute en los foros, la relación entre los microservicios y la arquitectura orientada a servicios (Service-Oriented Architecture), ¿son los microservicios una forma de implementar una SOA o son algo completamente distinto?
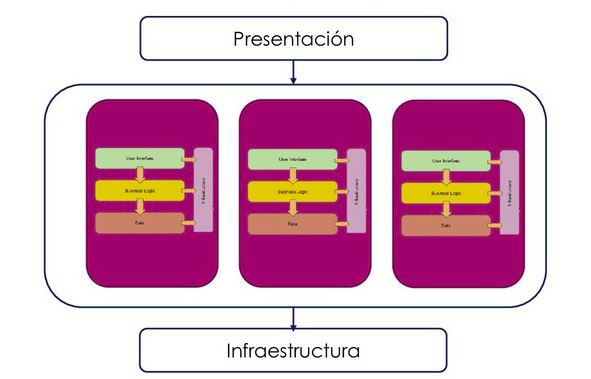
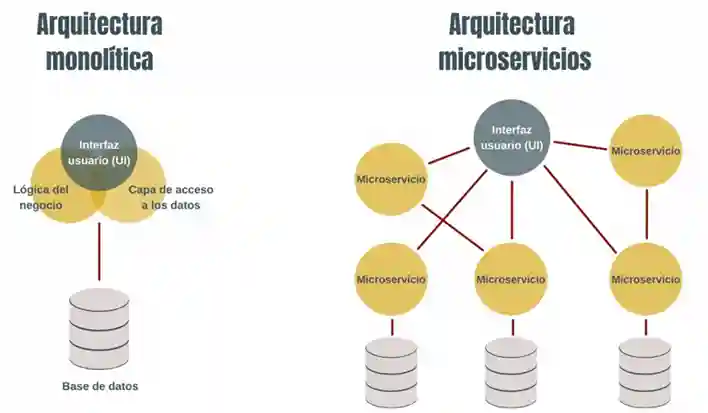
El enfoque SOA entró en escena en la segunda mitad de la década de los 90 como una primera aproximación para los problemas que presentaban las aplicaciones monolíticas. En estas aplicaciones, las distintas capas (interfaz con los usuarios, lógica de negocio, acceso a datos, etc.) están desarrolladas en un mismo programa y ejecutadas en una misma plataforma.
Esto no tiene por qué ser un problema cuando una aplicación es relativamente pequeña, pero los inconvenientes surgen cuando se le van añadiendo funcionalidades y crecen hasta convertirse en algo como lo que sugiere el término con que se las conoce de una forma un tanto peyorativa: algo rígido, pesado y primitivo.
La arquitectura SOA fue un primer paso en el proceso de desacoplamiento y división del monolito en componentes más ligeros que se articulan para dar lugar a un conjunto más flexible. El modelo no llega al nivel de desacoplamiento y flexibilidad de una arquitectura de microservicios porque son más los elementos comunes que comparten los servicios, por ejemplo:
- Para comunicarse entre sí utilizan un protocolo de comunicación común que es el Enterprise Service Bus (ESB), que es una parte esencial de este tipo de arquitectura y una de las que distinguen la arquitectura SOA de la arquitectura de microservicios. Este protocolo de comunicación introduce un elemento de rigidez al estar obligados los desarrolladores encargados de cada servicio a ajustarse a él.
- Aunque la regla es que los servicios compartan la base de datos, la definición no es tan rígida. Podemos encontrar implementaciones en las que los servicios compartan la misma base de datos, y otras con bases de datos independientes o compartidas por algunos de los servicios y no por todos.
Los microservicios
Sin entrar en el debate de si son o no una forma específica de implementar una arquitectura orientada servicios, los microservicios van más allá en el proceso de desacoplamiento y aislamiento de componentes.
Cada microservicio puede estar desarrollado en un lenguaje de programación y manejar su propio modelo de almacenamiento de datos. Podemos tener un microservicio desarrollado en Node.js y con una base de datos MongoDB, proporcionando datos que son consumidos por otro microservicio desarrollado en Java y con una base de datos de MySQL, y cada uno de ellos se puede estar ejecutando en un entorno diferente.
Además, como ya hemos dicho, los componentes de una arquitectura de microservicios no comparten un protocolo de comunicación común preestablecido. Para comunicarse entre sí y proporcionar los datos requeridos por el resto de los microservicios, cada uno implementa una API, y el resto de los microservicios es suficiente que conozcan el protocolo para conectarse a ella.
Las ventajas que aportan los microservicios:
- Modularidad. Al tratarse de servicios autónomos, se pueden desarrollar y desplegar de forma independiente. Además, un error en un servicio no debería afectar la capacidad de otros servicios para seguir trabajando según lo previsto.
- Escalabilidad. Como es una aplicación modular, se puede escalar horizontalmente cada parte según sea necesario, aumentando el escalado de los módulos que tengan un procesamiento más intensivo.
- Versatilidad. Al utilizar diferentes tecnologías y lenguajes de programación se puede adaptar cada funcionalidad a la tecnología más adecuada y rentable.
- Implementación sencilla. Por ser modulares, su implementación es más ágil que en aplicaciones monolíticas. Los microservicios facilitan la integración continua, y, a su vez, probar nuevas ideas y revertirlas si algo no funciona.
- Minimización de riesgos. El bajo costo de los errores permite experimentar, facilita la actualización del código y acelerar el tiempo de comercialización de las nuevas características. Además, la modularización permite detectar más fácilmente el origen de los errores y disminuir el tiempo necesario para resolverlos.
- Código reutilizable. Un servicio escrito para una determinada función se puede usar como un componente básico para otra característica. Esto permite que una aplicación arranque por sí sola, ya que los desarrolladores pueden crear nuevas capacidades sin tener que escribir código desde cero. Se pueden utilizar funcionalidades típicas (autenticación, trazabilidad, etc.) que ya han sido desarrolladas por terceros, no hace falta que el desarrollador las cree de nuevo.
- Agilidad en los cambios. Cada microservicio puede estar desarrollado sobre una tecnología diferente, por lo que puedes elegir la tecnología que mejor se adapte para la aplicación. Los equipos pueden trabajar de forma más independiente y rápida, acortando los tiempos del ciclo de desarrollo. Al ejecutarse cada microservicio en una plataforma independiente, se pueden detener o reiniciar para aplicar los cambios sin afectar al resto de la aplicación.
- Mantenimiento simple y barato. Al poder hacerse mejoras de un solo módulo y no tener que intervenir en toda la estructura, el mantenimiento es más sencillo y barato que en otras arquitecturas.
Microservicios y contenedores
Hoy en día resulta muy habitual que a la idea de microservicios se asocie la de contenedores, llegando en ocasiones a asimilarse como sinónimos. Por eso creemos muy conveniente definir lo que es un contenedor y su relación con la arquitectura de los microservicios.
En el ámbito de las tecnologías de la información, un contenedor es un método de virtualización a nivel de sistema operativo, extendiendo la función de la virtualización a nivel de hardware que desarrollan las aplicaciones de ejecución de máquina virtuales como VMWare, XEN, Proxmox, etc. En un contenedor se empaqueta y aísla el software de una aplicación, incluyendo las dependencias, sistema de archivos, configuración de red etc., todo excepto el sistema operativo.
De esta manera, sobre un mismo sistema operativo se pueden ejecutar distintas aplicaciones de forma aislada, compartiendo los recursos que ofrece el sistema operativo, pero sin entrar en conflicto. Son procesos aislados que no interfieren con el resto, se puede parar o reiniciar cada contenedor si la aplicación que ejecuta lo requiere, sin que el resto de las aplicaciones dejen de funcionar, y sin la pérdida de tiempo que supone el reinicio de un sistema operativo.
Dicho esto, queda claro que los contenedores están directamente relacionados con las tecnologías de la virtualización, de hecho, nada impide desarrollar un microservicio en una máquina virtual, o incluso en un servidor físico. Desde el otro lado de la ecuación, no hay nada que impida desarrollar y ejecutar toda una aplicación monolítica en un contenedor, salvo la limitación que impone el sistema operativo sobre el que se ejecuta el contenedor.
Resumiendo, de una manera un tanto burda, no todo lo que se ejecuta en un contenedor es un microservicio ni todo lo que se ejecuta fuera de un contenedor deja de serlo.
Con todo esto no queremos dar a entender que la asociación de ideas de la que hablamos al inicio del apartado no esté justificada o negar que exista. Por supuesto que se da, pero no porque se desarrollen con este objetivo, sino porque entre ambas tecnologías se ha llegado a una especie de convergencia evolutiva. Sin haberse desarrollado para ello hay un momento en el que se descubre que los contenedores pueden ser la solución a los requisitos de agilidad, escalabilidad y portabilidad que presentan los microservicios.
Del origen y evolución de los microservicios ya hemos hablado. Por su lado, los contenedores surgieron como una forma de ejecutar aplicaciones de dudoso nivel de seguridad, limitando su acceso a un directorio del sistema operativo para que ninguno de sus procesos pudiera acceder y modificar los archivos del sistema. La limitación se extendió para que tampoco se pudiese acceder al subsistema de red y otros elementos del kernel. Con esta intención los sistemas operativos FREEBSD, Solaris y Linux desarrollaron las jaulas, las zonas y Linux Vserver, respectivamente.
Más adelante surgirían las que hoy son las aplicaciones más extendidas para trabajar con contenedores: Docker y Kubernetes. El primero es el software que ejecuta los contenedores y el segundo es una herramienta de orquestación de contenedores. Docker se puede instalar en multitud de sistemas operativos incluyendo equipos personales, y una vez que ya lo tenemos podemos descargar imágenes desde un repositorio centralizado, Docker Hub es el más habitual, pero hay otros.
Descargada la imagen que más se ajuste a nuestras necesidades podemos ejecutar un contenedor, hacer las modificaciones que necesitemos, cargar nuestro código, etc., y, llegado el momento, crear nuestra propia imagen y subirla al repositorio para desde ahí ser distribuida y ejecutada en cualquier equipo que tenga instalado Docker sin que tengamos ningún problema con las dependencias porque está empaquetadas en la imagen, quedando así cubierto el requisito de portabilidad.
Esta situación puede ser suficiente para el escenario de un pequeño equipo de desarrolladores que hacen cambios en una pequeña aplicación compuesta por unos pocos contenedores, o para un entorno de pruebas. Pero cuando hay que gestionar un entorno de producción con cientos de contenedores repartidos entre varios servidores que ejecutan Docker, gestionar despliegues, automatizar escalados y desescaladas, repartir la carga, etc., se hace indispensable una herramienta de orquestación como Kubernetes.
Son muchas las posibilidades que ofrecen para la orquestación de contenedores aplicaciones como Kubernetes. Explicarlas queda fuera del alcance de este artículo, pero el resumen que hemos hecho debe ser suficiente para entender cómo se cubren las necesidades de modularidad, escalabilidad, versatilidad y agilidad que se intentan satisfacer desacoplando una aplicación en microservicios.
¿Se podría conseguir el mismo objetivo con máquinas virtuales?, si tenemos en cuenta el tiempo que se necesita para arrancar un sistema operativo y lo comparamos con el que tarda en ejecutarse un proceso, resulta evidente que son una tecnología desfasada.
Microservicios en AWS
AWS ofrece varias soluciones para la ejecución y orquestación de microservicios y contenedores:
AWS ECS, Elastic Container Service

Es el Servicio de AWS para administrar y orquestar contenedores. Para configurar el servicio se debe definir una “tarea” en la que se indican los contenedores que se quieren desplegar, las imágenes que se deben utilizar, los registros en los que se pueden encontrar y las instancias de EC2 en las que queremos que se ejecuten. También se definen las reglas por las que se debe guiar el orquestador para decidir la cantidad de contenedores de cada tipo que debe haber en ejecución.
Si es necesario aumentar o disminuir la cantidad de instancias de EC2 para poder ejecutar la cantidad de contenedores requeridos, ECS se integra con el servicio de auto escalado de máquinas virtuales. Yendo un paso más allá, en lugar de EC2, podemos definir en la tarea que para ejecutar los contenedores se utilice el servicio de Fargate, y así olvidarnos de la creación de instancias de EC2 y su escalado, aunque también de su control.
Además de los servicios ya mencionados ECS se integra con otros servicios de AWS.
- IAM (Identity and Access Management). para dar permisos de acceso a específico a cada contenedor.
- ECR (Elastic Container Service). el repositorio de imágenes para contenedores de AWS.
- Servicios de implementación y despliegue continuo: para ilustrar lo que se puede llegar a hacer con la integración con esta serie de servicios sirva el ejemplo de un servicio que monitoriza cambios en el repositorio del código fuente de la aplicación (Code Commit, GIT Hub, etc.), construir una imagen Docker a partir de esos cambios, subir la imagen al repositorio (Docker Hub o ECR) y por último actualizar ES para que utilice la nueva imagen.
- CloudWatch. los logs de los distintos contenedores se envían al servicio de logs de AWS, desde donde son más fáciles de consultar y no consumen el disco de los contenedores.
- Elastic Load Balancing. para distribuirla carga entre los distintos contenedores e instancias del clúster.
AWS EKS, Elastic Kubernetes Service

Amazon EKS es el servicio de AWS para orquestar clústers Kubernetes. Al igual que en ECS, el clúster se puede desplegar en instancias de EC2 o en Fargate, con lo cual nos ahorramos la tarea de gestionar el auto escalado de máquinas. La desventaja frente a ECS es que la integración con otros servicios de AWS no es tan completa, y la ventaja es la facilidad de migración entre clústers de Kubernetes.
Si ya tenemos una infraestructura de Kubernetes on premise o en otro proveedor Cloud (Google Kubernetes Engine, Azure Kubernetes Service, etc.) y queremos desplegarla en otro medio, el código de Kubernetes es aprovechable prácticamente en un 100%. Si queremos mover una infraestructura de Kubernetes a ECS, o si queremos migrarla de ECS a Kubernetes, tenemos que convertir el código de Kubernetes en una tarea de ECS o viceversa, lo cual implica conocer las 2 tecnologías y un tiempo para tener en cuenta.
AWS Lambda y API Gateway
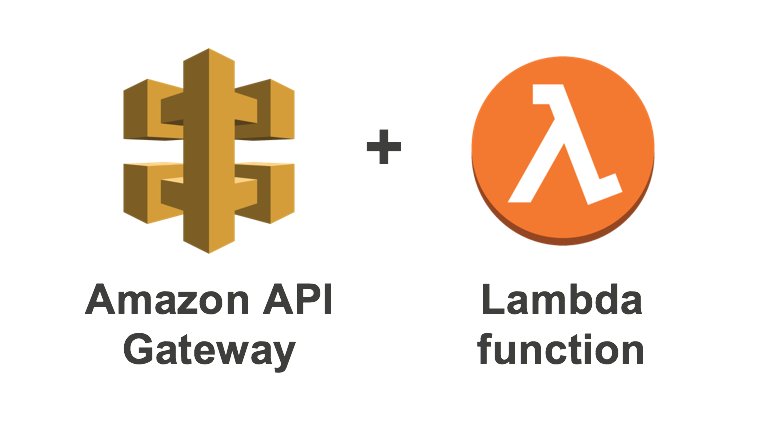
Lambda forma parte del modelo serverless de AWS, muy útil para crear microservicios sin utilizar contenedores porque lo que permite ejecutar código sin servidores, instancias de EC2, máquinas virtuales, etc. Podemos definir una programación diaria, como se hace con cron en Linux o tareas programadas en Windows, para que se ejecute el código, o podemos hacer que responda a ciertos eventos desencadenados por otros servicios de AWS.
Para la creación de microservicios lo natural es que Lambda se integre con API Gateway, el servicio de AWS para desarrollar APIs, y que el código Lambda se desencadena a partir de las llamadas que a su API hagan otros microservicios.
Monolitos modulares, ¿el final de los microservicios?
Si echamos un vistazo a la gráfica de InfoQ, sí que parece que dentro del campo del desarrollo y la arquitectura de software los microservicios han llegado a la mayoría de edad, que son algo desfasados y les queda poco para salir de escena.
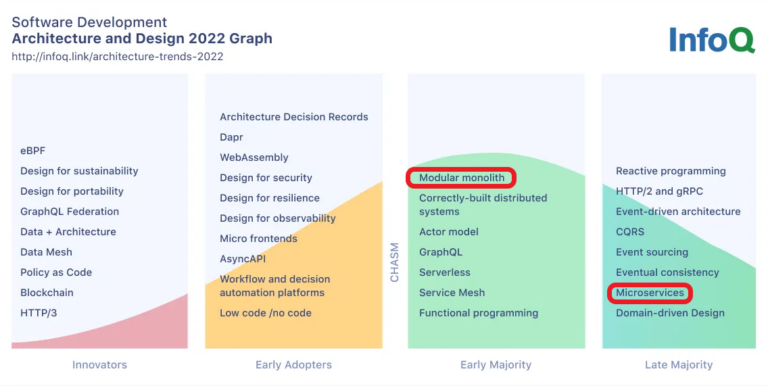
Aunque surgieran como solución a los problemas de la arquitectura monolítica, no hay duda de que tienen una serie de desventajas e inconvenientes que no se pueden pasar por alto, por ejemplo:
- Desde un primer momento, es mayor la complejidad en la implantación de un modelo de microservicios que en un modelo monolítico, y es mucho más grande el tiempo inicial necesario para planificar su desarrollo.
- Dificultad para hacer pruebas globales.
- También son importantes los problemas que surgen al constar con varias bases de datos:
- Problemas transaccionales: cómo se orquesta un rollback cuando son varias las bases de datos en juego.
- Problemas de integridad: cómo se garantiza la coherencia entre los datos repartidos en varias bases de datos.
- Mayor consumo de recursos: cuando hay que asignar recursos a cada elemento, ante la dificultad de ajustar lo habitual es sobredimensionar. Si multiplicamos el pequeño sobredimensionamiento de cada microservicio el resultado no es tan pequeño.
- Existencia “absurda” de algunos microservicios por ser de escasa entidad y desempeñar una funcionalidad que podría realizar otro microservicio existente.
Lo que propone la arquitectura de monolitos modulares es desarrollar la aplicación como un monolito dividido en módulos que no tengan el mismo nivel de desacoplamiento que los microservicios, pero teniendo en mente la posibilidad de que en algún momento uno de esos módulos se pueda convertir en un microservicio, y facilitando su posible migración futura. Para ello cada módulo define su propio API para ofrecer el medio de comunicación con el resto de módulos y que el código interno quede aislado para proteger su integridad.
Los equipos de desarrollo se pueden centrar en la funcionalidad de cada módulo, pero deben comprender que los monolitos modulares no brindan todos los beneficios de los microservicios, especialmente cuando se trata de diversificar la tecnología y las opciones de lenguaje. Además, dado que las aplicaciones necesitan ejecutar código dentro de un solo tiempo de ejecución, existe una oportunidad limitada para mezclar esos entornos de tiempo de ejecución.
De esta manera se ofrece una solución al problema de la complejidad que presenta una migración completa de una aplicación monolítica a una infraestructura de microservicios, o de definición e implantación inicial de una arquitectura de microservicios y de la existencia de microservicios absurdamente pequeños.
A fin de cuentas, lo que propone este modelo es un poco de sentido común para encontrar un término medio entre los 2 extremos que representan las arquitecturas monolíticas y las de microservicios. Término medio que ya habían buscado los equipos que se hubiesen enfrentado al reto de elegir entre ambos extremos, y al que cada uno hubiese dado una solución ateniéndose a las circunstancias.
Resumiendo, también el sentido común nos dice que todas estas tecnologías de las que hemos hablado pueden existir y complementarse, y que la llegada de una no tiene por qué implicar la desaparición de las otras.