

¿Tienes un sitio web o un ecommerce y deseas publicarlo/desplegarlo en un ecosistema Cloud como puede ser Amazon Web Services, Google Cloud o Microsoft Azure aplicando los criterios profesionales críticos y con garantías de que el planteamiento es el adecuado? Entonces, continúa leyendo.En este artículo realizaremos un ejercicio completo de arquitectura de servicios en Amazon Web Services (AWS) para la implementación del popular gestor de contenidos WordPress, aunque muchos de los criterios y razonamientos aquí expuestos son de aplicación para abordar el diseño y despliegue de soluciones web como Prestashop, Joomla, Magento u otro site web adhoc.Para ello, partiremos de una base sencilla e iremos añadiendo mayor complejidad a los requisitos con el objetivo de resolver en cada paso una necesidad concreta, comentando los beneficios y desventajas en cada uno de ellos, de esta manera iremos revisando los factores más relevantes que determinan la creación de un arquitectura de servicios en AWS escalable, segura y optimizada.Siguiendo estos pasos, cualquier arquitecto Cloud comprobará que has realizado un trabajo con criterio, bien fundamentado y con un pensamiento que garantiza aspectos críticos. Con esta arquitectura podremos acceder directamente al servidor virtual mediante SSH, SFTP o cualquier otro protocolo siempre que estén abiertas las reglas en el grupo de seguridad de la instancia EC2. No habrá ninguna restricción a la operación de WordPress (o en general de cualquier otro CMS) respecto a como se haría en cualquier otro servicio de hosting:Con este sencillo cambio, obtendremos un sitio mucho más estable al no tener al servidor web compitiendo con la base de datos por recursos de nuestra instancia EC2 a la vez que descargamos sobre RDS la carga de trabajo derivada del mantenimiento y operación de la base de datos.Como contraprestación podríamos añadir que, al tratarse de un servicio gestionado, no disponemos de credenciales root en el servidor de base de datos. RDS proporciona un usuario con privilegios elevados (aunque no dispone del privilegio global SUPER) e interfaces especiales para la ejecución de procedimientos privilegiados (procedimientos almacenados y consola/API de RDS). A aquellos administradores que gusten de tener un control absoluto del servidor esto puede suponer un problema, pero lo cierto es que para el caso que nos ocupa y dados todos los beneficios que aporta el servicio, creemos que RDS es con mucho la opción más recomendable.En esta arquitectura desaparece la ElasticIP adjunta a nuestra instancia EC2 y se han introducido múltiples componentes:AWS proporciona numerosos grupos de reglas para implementar fácilmente protecciones ante las principales amenazas del momento, pero existen también grupos de reglas de fabricantes especializados como F5 o Fortigate, o incluso pueden implementarse reglas completamente personalizadas. A continuación detallaremos los grupos de reglas suministrados directamente por AWS con aplicación directa en cualquier instalación de WordPress:El principal cambio en este diseño es la provisión de un servidor web adicional (podrían ser más, tantos como creamos conveniente) detrás de nuestro balanceador de carga. Este servidor adicional reside en una zona de disponibilidad alternativa para mayor seguridad, y comparte con el servidor inicial tanto la base de datos RDS como una carpeta compartida NFS hospedada en un sistema de ficheros regional (replicado en múltiples AZs) de Elastic File System. Por simplicidad, en esta arquitectura la carpeta compartida contendrá todo el document_root del servidor web, lo que incluye tanto el core de WordPress como plugin, temas y la biblioteca de medios; esto permite minimizar el impacto operacional sobre las acciones del panel de WordPress que puede tener el compartir únicamente una subcarpeta.En el caso de la base de datos, para dotar de alta disponibilidad basta con activar la opción de despliegue Multi-AZ en nuestra instancia RDS. Esto desplegará automáticamente una réplica de lectura oculta en una zona de disponibilidad alternativa. En caso de fallo en la instancia primaria, AWS se encarga de ejecutar automáticamente el procedimiento de failover consistente en promocionar la réplica de lectura a maestro y modificar el DNS para apuntar a la “ex-réplica”. Asimismo, cada vez que se requiera ejecutar acciones de TI como parcheo, redimensionamientos o reconfiguraciones con reinicio obligatorio de la instancia, Amazon RDS aplicará los cambios primero en la réplica para seguidamente realizar un failover y finalmente poder operar sobre la instancia restante. Todo con un corte de servicio de unos pocos segundos.Por su parte, Application Load Balancer se trata de un servicio inherentemente altamente disponible y no permite ser desplegado en una única zona de disponibilidad con lo que no es necesaria ninguna acción.En cuanto a la pasarela de NAT, cada instancia de NAT Gateway es altamente disponible dentro de su zona de disponibilidad. En caso de fallo global en una zona de disponibilidad dejaríamos sin servicio a toda la plataforma de servidores, con lo que es recomendable que las subredes privadas de cada AZ hagan uso de una NAT Gateway dedicada.Con todos estos cambios implementados, ninguna pieza de nuestra infraestructura supone un punto único de fallo. Todos los componentes están replicados en zonas de disponibilidad separadas y la arquitectura es lo suficientemente resiliente como para soportar el fallo de toda una zona de disponibilidad de la región donde hospedemos nuestra plataforma.La contraprestación más destacable en este caso es el significativo aumento de costes, ya que respecto del diseño del apartado 4 prácticamente habremos duplicado el coste de la plataforma. Adicionalmente, se nos presenta la necesidad de administrar múltiples servidores web, lo que aumentará la carga de trabajo de los operadores y podría redundar en problemas de inconsistencia si no se tiene un control riguroso o automatizado de la configuración de estos. Para estos casos, siempre recomendamos hacer uso de sistemas de gestión de la configuración como Puppet, Ansible o Chef y evitar la administración manual de cualquier servidor.El resto de los servicios de nuestra plataforma (Application Load Balancer, NAT Gateway, EFS…) son inherentemente escalables y no necesitan acciones concretas.Es altamente recomendable tener un procedimiento lo más automatizado posible para el mantenimiento de las plantillas de despliegue de instancias EC2, ya que la aplicación de cambios y parches de seguridad en nuestros servidores pasará a partir de este momento por la creación de una nueva plantilla de despliegue y rotar todos los servidores activos en un momento dado. Herramientas como Hashicorp Packer o EC2 Image Builder en combinación con servicios de CI/CD son ideales para este fin.Este cambio tiene un impacto muy significativo en la operación de nuestros servidores web y en un primer momento puede resultar difícil adoptar el cambio por parte de los operadores, pero una vez en marcha, los beneficios económicos y la estabilidad de la plataforma ante picos de demanda o incluso ante fallos operacionales puntuales justifican con creces el cambio. Si además se consigue implementar con éxito pipelines para la construcción automatizada de imágenes y plantilla de lanzamiento, rápidamente será evidente la ganancia en términos de agilidad operacional.Como contraprestaciones en este caso tendríamos dos:Por un lado, la introducción de sistemas de cacheo puede dificultar en ciertos momentos la gestión de contenidos. Es habitual que administradores no experimentados en el uso de este tipo de sistemas piensen que sus cambios no tienen ningún efecto en el frontend, cuando realmente lo único que hay que hacer es lanzar un proceso de vaciado de cachés para que sus cambios se propaguenEn segundo lugar, el potencial incremento de costes de infraestructura debido a la adición de nuevos componentes. Sin embargo, gracias a la descarga de trabajo para la entrega de contenido estático y la significativa mejora de rendimiento en el renderizado de PHP por la introducción de múltiples sistemas de cacheo de contenido redundarán en una menor utilización de recursos tanto en los servidores web como en la base de datos, las piezas de mayor coste de toda la plataforma, con lo que es de esperar no solo una mejora de rendimiento sino incluso una reducción de costes por el menor uso de capacidad en los componentes principales.El uso de AWS Fargate implica además que no necesitamos provisionar instancias EC2 en nuestro clúster de ECS. Amazon se encarga de gestionar la infraestructura de ejecución de contenedores y solo pagamos por la CPU y memoria que utilicen nuestros contenedores. Esto hace que ya no necesitemos administrar imágenes de instancia periódicamente ni preocuparnos por el parcheado de servidores, ya que estas tareas pasan a estar gestionadas por AWS.La contraprestación de este cambio es la impedancia de entrada que supone el cambio de paradigma. Para aquellos administradores y desarrolladores acostumbrados a la forma “clásica” de trabajo, el cambio a contenedores puede suponerles una dificultad añadida para desempeñar su trabajo. Sin embargo, las garantías de consistencia en los despliegues, la agilidad que toma el proceso de desarrollo y la facilidad para replicar entornos suelen justificar sobradamente el cambio.
Con esta arquitectura podremos acceder directamente al servidor virtual mediante SSH, SFTP o cualquier otro protocolo siempre que estén abiertas las reglas en el grupo de seguridad de la instancia EC2. No habrá ninguna restricción a la operación de WordPress (o en general de cualquier otro CMS) respecto a como se haría en cualquier otro servicio de hosting:Con este sencillo cambio, obtendremos un sitio mucho más estable al no tener al servidor web compitiendo con la base de datos por recursos de nuestra instancia EC2 a la vez que descargamos sobre RDS la carga de trabajo derivada del mantenimiento y operación de la base de datos.Como contraprestación podríamos añadir que, al tratarse de un servicio gestionado, no disponemos de credenciales root en el servidor de base de datos. RDS proporciona un usuario con privilegios elevados (aunque no dispone del privilegio global SUPER) e interfaces especiales para la ejecución de procedimientos privilegiados (procedimientos almacenados y consola/API de RDS). A aquellos administradores que gusten de tener un control absoluto del servidor esto puede suponer un problema, pero lo cierto es que para el caso que nos ocupa y dados todos los beneficios que aporta el servicio, creemos que RDS es con mucho la opción más recomendable.En esta arquitectura desaparece la ElasticIP adjunta a nuestra instancia EC2 y se han introducido múltiples componentes:AWS proporciona numerosos grupos de reglas para implementar fácilmente protecciones ante las principales amenazas del momento, pero existen también grupos de reglas de fabricantes especializados como F5 o Fortigate, o incluso pueden implementarse reglas completamente personalizadas. A continuación detallaremos los grupos de reglas suministrados directamente por AWS con aplicación directa en cualquier instalación de WordPress:El principal cambio en este diseño es la provisión de un servidor web adicional (podrían ser más, tantos como creamos conveniente) detrás de nuestro balanceador de carga. Este servidor adicional reside en una zona de disponibilidad alternativa para mayor seguridad, y comparte con el servidor inicial tanto la base de datos RDS como una carpeta compartida NFS hospedada en un sistema de ficheros regional (replicado en múltiples AZs) de Elastic File System. Por simplicidad, en esta arquitectura la carpeta compartida contendrá todo el document_root del servidor web, lo que incluye tanto el core de WordPress como plugin, temas y la biblioteca de medios; esto permite minimizar el impacto operacional sobre las acciones del panel de WordPress que puede tener el compartir únicamente una subcarpeta.En el caso de la base de datos, para dotar de alta disponibilidad basta con activar la opción de despliegue Multi-AZ en nuestra instancia RDS. Esto desplegará automáticamente una réplica de lectura oculta en una zona de disponibilidad alternativa. En caso de fallo en la instancia primaria, AWS se encarga de ejecutar automáticamente el procedimiento de failover consistente en promocionar la réplica de lectura a maestro y modificar el DNS para apuntar a la “ex-réplica”. Asimismo, cada vez que se requiera ejecutar acciones de TI como parcheo, redimensionamientos o reconfiguraciones con reinicio obligatorio de la instancia, Amazon RDS aplicará los cambios primero en la réplica para seguidamente realizar un failover y finalmente poder operar sobre la instancia restante. Todo con un corte de servicio de unos pocos segundos.Por su parte, Application Load Balancer se trata de un servicio inherentemente altamente disponible y no permite ser desplegado en una única zona de disponibilidad con lo que no es necesaria ninguna acción.En cuanto a la pasarela de NAT, cada instancia de NAT Gateway es altamente disponible dentro de su zona de disponibilidad. En caso de fallo global en una zona de disponibilidad dejaríamos sin servicio a toda la plataforma de servidores, con lo que es recomendable que las subredes privadas de cada AZ hagan uso de una NAT Gateway dedicada.Con todos estos cambios implementados, ninguna pieza de nuestra infraestructura supone un punto único de fallo. Todos los componentes están replicados en zonas de disponibilidad separadas y la arquitectura es lo suficientemente resiliente como para soportar el fallo de toda una zona de disponibilidad de la región donde hospedemos nuestra plataforma.La contraprestación más destacable en este caso es el significativo aumento de costes, ya que respecto del diseño del apartado 4 prácticamente habremos duplicado el coste de la plataforma. Adicionalmente, se nos presenta la necesidad de administrar múltiples servidores web, lo que aumentará la carga de trabajo de los operadores y podría redundar en problemas de inconsistencia si no se tiene un control riguroso o automatizado de la configuración de estos. Para estos casos, siempre recomendamos hacer uso de sistemas de gestión de la configuración como Puppet, Ansible o Chef y evitar la administración manual de cualquier servidor.El resto de los servicios de nuestra plataforma (Application Load Balancer, NAT Gateway, EFS…) son inherentemente escalables y no necesitan acciones concretas.Es altamente recomendable tener un procedimiento lo más automatizado posible para el mantenimiento de las plantillas de despliegue de instancias EC2, ya que la aplicación de cambios y parches de seguridad en nuestros servidores pasará a partir de este momento por la creación de una nueva plantilla de despliegue y rotar todos los servidores activos en un momento dado. Herramientas como Hashicorp Packer o EC2 Image Builder en combinación con servicios de CI/CD son ideales para este fin.Este cambio tiene un impacto muy significativo en la operación de nuestros servidores web y en un primer momento puede resultar difícil adoptar el cambio por parte de los operadores, pero una vez en marcha, los beneficios económicos y la estabilidad de la plataforma ante picos de demanda o incluso ante fallos operacionales puntuales justifican con creces el cambio. Si además se consigue implementar con éxito pipelines para la construcción automatizada de imágenes y plantilla de lanzamiento, rápidamente será evidente la ganancia en términos de agilidad operacional.Como contraprestaciones en este caso tendríamos dos:Por un lado, la introducción de sistemas de cacheo puede dificultar en ciertos momentos la gestión de contenidos. Es habitual que administradores no experimentados en el uso de este tipo de sistemas piensen que sus cambios no tienen ningún efecto en el frontend, cuando realmente lo único que hay que hacer es lanzar un proceso de vaciado de cachés para que sus cambios se propaguenEn segundo lugar, el potencial incremento de costes de infraestructura debido a la adición de nuevos componentes. Sin embargo, gracias a la descarga de trabajo para la entrega de contenido estático y la significativa mejora de rendimiento en el renderizado de PHP por la introducción de múltiples sistemas de cacheo de contenido redundarán en una menor utilización de recursos tanto en los servidores web como en la base de datos, las piezas de mayor coste de toda la plataforma, con lo que es de esperar no solo una mejora de rendimiento sino incluso una reducción de costes por el menor uso de capacidad en los componentes principales.El uso de AWS Fargate implica además que no necesitamos provisionar instancias EC2 en nuestro clúster de ECS. Amazon se encarga de gestionar la infraestructura de ejecución de contenedores y solo pagamos por la CPU y memoria que utilicen nuestros contenedores. Esto hace que ya no necesitemos administrar imágenes de instancia periódicamente ni preocuparnos por el parcheado de servidores, ya que estas tareas pasan a estar gestionadas por AWS.La contraprestación de este cambio es la impedancia de entrada que supone el cambio de paradigma. Para aquellos administradores y desarrolladores acostumbrados a la forma “clásica” de trabajo, el cambio a contenedores puede suponerles una dificultad añadida para desempeñar su trabajo. Sin embargo, las garantías de consistencia en los despliegues, la agilidad que toma el proceso de desarrollo y la facilidad para replicar entornos suelen justificar sobradamente el cambio.
Servidor virtual único (monolítico)
Este tipo de implantación es la más sencilla de llevar a cabo y la más similar en su concepto a lo que ofrecen proveedores VPS clásicos o incluso servicios de hosting compartido. Las únicas piezas de que consta nuestra infraestructura son:- Instancia EC2 Linux donde ejecutarán todos los componentes de WordPress: Servidor web, PHP y el motor de base de datos.
- ElasticIP que adjuntaremos a la instancia anterior para dotarla de una IP pública persistente.
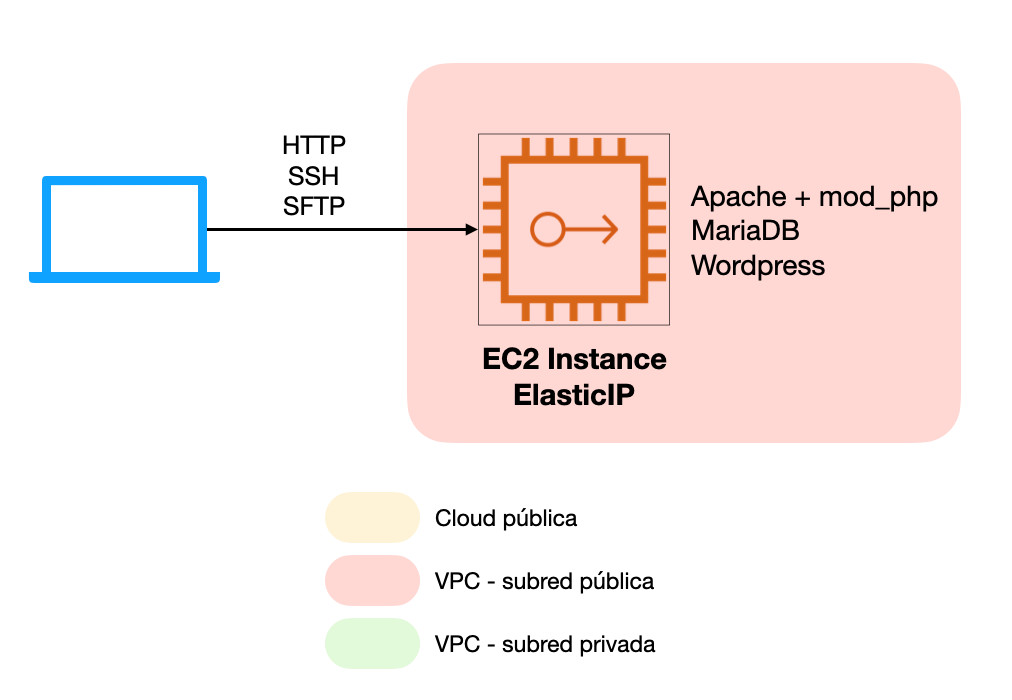 Con esta arquitectura podremos acceder directamente al servidor virtual mediante SSH, SFTP o cualquier otro protocolo siempre que estén abiertas las reglas en el grupo de seguridad de la instancia EC2. No habrá ninguna restricción a la operación de WordPress (o en general de cualquier otro CMS) respecto a como se haría en cualquier otro servicio de hosting:
Con esta arquitectura podremos acceder directamente al servidor virtual mediante SSH, SFTP o cualquier otro protocolo siempre que estén abiertas las reglas en el grupo de seguridad de la instancia EC2. No habrá ninguna restricción a la operación de WordPress (o en general de cualquier otro CMS) respecto a como se haría en cualquier otro servicio de hosting:- Todas las acciones realizadas desde el panel de WordPress se ven reflejadas inmediatamente en el frontend (Actualización de plugin, temas, core de WordPress, documentos e imágenes…)
- El servidor es fácilmente administrable vía SSH, solo es necesario que el puerto TCP22 esté abierto para nuestra dirección IP en el grupo de seguridad para poder iniciar una sesión.
- Para subir contenidos al servidor podemos utilizar SFTP o cualquier otro protocolo de transferencia de archivos. De nuevo, basta con hacer la gestión correspondiente en el grupo de seguridad de la instancia para desbloquear la conectividad.
- El acceso a servicios sensibles como SSH o la base de datos puede verse comprometidosi no se hace un uso responsable de las reglas del grupo de seguridad de la instancia
- Las operaciones de TI como el parcheado de seguridad, redimensionamiento o incluso modificación de ciertas configuraciones conllevan cortes de servicio
- Escalabilidad estrictamente vertical
- La monitorización disponible de serie se limita a métricas del hipervisor de la instancia EC2; para poder tener algo razonable habría que extender las métricas disponibles mediante agentes y sistemas de recolección dedicados como Cloudwatch, NewRelic, Zabbix o similares.
- Administración manual, muy sujeta a errores humanos y complicada de mantener consistente en el tiempo.
- El control de copias de seguridad puede ser algo rudimentario si no se implementan soluciones de propósito específico como AWS Backup
Base de datos en servidor dedicado e independiente
En cualquier sistema de gestión de contenidos, el principal cuello de botella (y donde suelen producirse normalmente los primeros problemas de rendimiento de aplicaciones LAMP) es la base de datos relacional; en el caso de WordPress: MySQL o MariaDB.Las bases de datos relacionales suelen ser los principales consumidores de recursos de los servidores con una arquitectura como la del apartado 1, y por tanto la pieza que más dedicación requiere en términos de monitorización, operación, optimización y tareas de respaldo. Es por ello que la recomendación sea siempre separar la base de datos relacional del servidor web para dotarla de sus propios recursos de cómputo y almacenamiento, así como tener bien aislado este subsistema del tráfico proveniente del exterior.Para este fin, nuestra recomendación es hacer uso de instancias de Amazon Relational Database Service. Este servicio permite implementar rápidamente instancias compatibles con los principales motores de base de datos del mercado y añadiendo las siguientes ventajas respecto de lo que sería un servidor de base de datos autogestionado:- Procesos de TI automatizados: Parcheado, reconfiguración, escalado…
- Análisis de utilización continuo para generar sugerencias sobre prácticas recomendadas.
- Backup integrado con posibilidad de recuperar a cualquier punto en el tiempo
- Métricas de rendimiento de propósito específico y paneles de monitorización avanzados
- Recolección de logs de auditoría y control de cambios
- Opciones de alta disponibilidad y escalado horizontal con réplicas de lectura
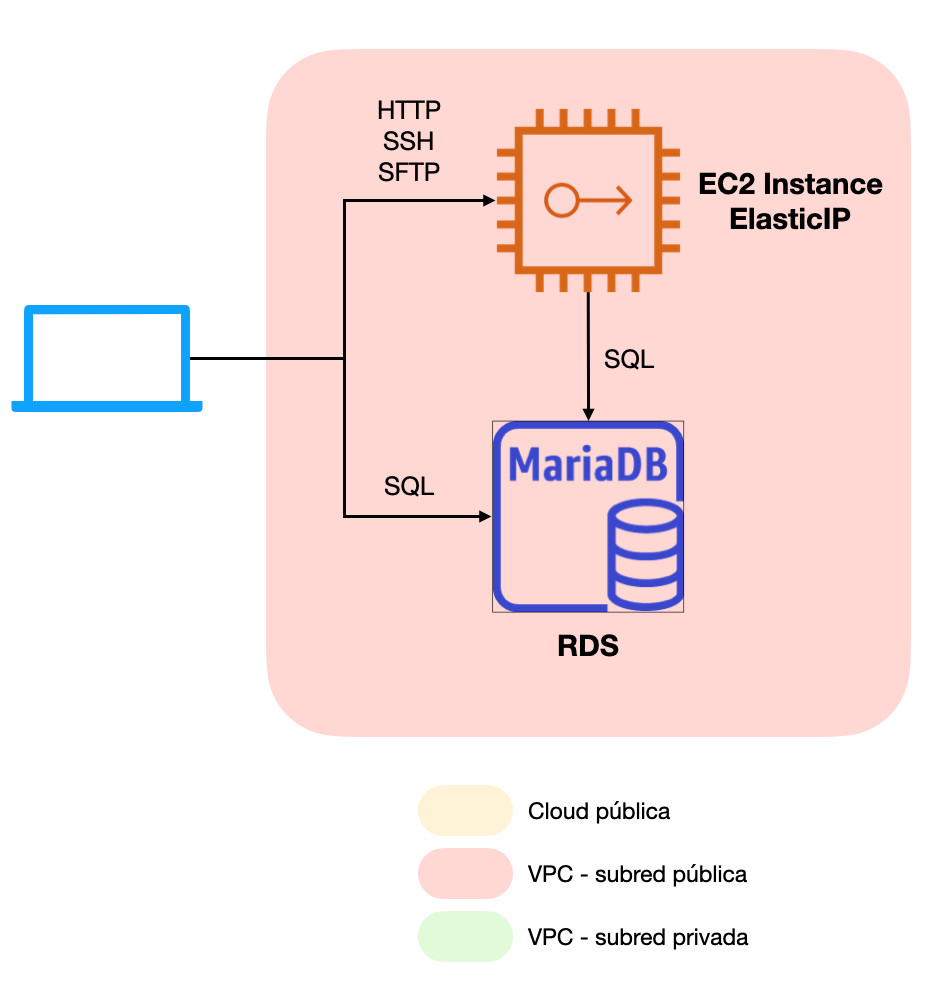 Con este sencillo cambio, obtendremos un sitio mucho más estable al no tener al servidor web compitiendo con la base de datos por recursos de nuestra instancia EC2 a la vez que descargamos sobre RDS la carga de trabajo derivada del mantenimiento y operación de la base de datos.Como contraprestación podríamos añadir que, al tratarse de un servicio gestionado, no disponemos de credenciales root en el servidor de base de datos. RDS proporciona un usuario con privilegios elevados (aunque no dispone del privilegio global SUPER) e interfaces especiales para la ejecución de procedimientos privilegiados (procedimientos almacenados y consola/API de RDS). A aquellos administradores que gusten de tener un control absoluto del servidor esto puede suponer un problema, pero lo cierto es que para el caso que nos ocupa y dados todos los beneficios que aporta el servicio, creemos que RDS es con mucho la opción más recomendable.
Con este sencillo cambio, obtendremos un sitio mucho más estable al no tener al servidor web compitiendo con la base de datos por recursos de nuestra instancia EC2 a la vez que descargamos sobre RDS la carga de trabajo derivada del mantenimiento y operación de la base de datos.Como contraprestación podríamos añadir que, al tratarse de un servicio gestionado, no disponemos de credenciales root en el servidor de base de datos. RDS proporciona un usuario con privilegios elevados (aunque no dispone del privilegio global SUPER) e interfaces especiales para la ejecución de procedimientos privilegiados (procedimientos almacenados y consola/API de RDS). A aquellos administradores que gusten de tener un control absoluto del servidor esto puede suponer un problema, pero lo cierto es que para el caso que nos ocupa y dados todos los beneficios que aporta el servicio, creemos que RDS es con mucho la opción más recomendable.Redes privadas como factor de seguridad
A medida que nuestro sitio web crezca en popularidad, se volverá más propenso a recibir ataques por parte de terceros que intenten extraer información privilegiada o incluso tomar el control de nuestro servidor para hacer un uso malicioso del mismo.Dado que la arquitectura en este punto aún no dispone de redes privadas, todos los componentes disponen de IPs públicas y, si por un descuido o una mala praxis a la hora de gestionar las reglas de grupos de seguridad algún puerto sensible queda abierto al exterior (TCP22 para el servicio SSH de nuestro servidor web o TCP3306 para la base de datos RDS), estos quedarían disponibles para que cualquier atacante “pruebe suerte” directamente conectándose a dichos servicios de alta sensibilidad.Una de las mayores recomendaciones que se puede hacer a la hora de securizar cualquier infraestructura de servidores es la implementación de redes privadas únicamente accesibles mediante servicios de seguridad de propósito específico tales como VPNs, instancias Bastion o, como en el caso que veremos a continuación, AWS Systems Manager. En esta arquitectura desaparece la ElasticIP adjunta a nuestra instancia EC2 y se han introducido múltiples componentes:
En esta arquitectura desaparece la ElasticIP adjunta a nuestra instancia EC2 y se han introducido múltiples componentes:- Subredes públicas y privadas de Amazon VPC. Desde las subredes públicas se tendrá acceso directo a Internet y los recursos que residan en ella tendrán sus IPs públicas, mientras que en las redes privadas todos los recursos desplegados tienen exclusivamente direcciones IP de área local.
- Para poder acceder a Internet desde las subredes privadas es necesario utilizar un dispositivo enrutador intermedio que ejecute NAT
- Para poder acceder a recursos de las redes privadas es necesario utilizar algún servicio de proxy o bastión que a su vez ofrezca algún tipo de interfaz de conectividad segura al exterior.
- NAT Gateway. Este servicio gestionado de AWS permite implementar de forma sencilla, escalable y altamente disponible un dispositivo de NAT en subredes públicas para proporcionar conectividad con Internet a los servicios en redes privadas.
- Application Load Balancer. Implementado para la exposición de puntos de enlace HTTP y HTTPS en subredes públicas.
- AWS Certificate Manager. Gestor de certificados SSL para balanceadores de carga de AWS. Podemos utilizar este mismo servicio para la emisión y rotación automática de certificados (al más puro estilo Let’s Encrypt) o bien importar nuestros certificados SSL.
- AWS Systems Manager. Servicio gestionado de administración de servidores Linux y Windows. Lo utilizaremos para poder iniciar sesiones administrativas en nuestra instancia EC2 sin necesidad de tener que abrir el puerto TCP22 a ningún origen.
- Nuestros servidores no tienen ningún puerto directamente accesible desde internet y todo el tráfico pasa por los servicios gestionados de AWS, los cuales pasan auditorías de seguridad periódicas y cumplen con los principales estándares de seguridad existentes.
- Application Load Balancer implementa procesos de anulación automática de cabeceras HTTP inválidas y facilita a los operadores elegir los algoritmos de encriptación en tránsito con solo unos pocos clics en la consola de AWS.
- Application Load Balancer se integra de serie con AWS Shield Standard para recibir protecciones ante ataques DoS en capa 3
- Con Application Load Balancer pueden implementarse fácilmente reglas de redirección HTTP->HTTPS o denegar todo el tráfico que no cumpla ciertas reglas básicas como por ejemplo indicar una cabecera Host para su nombre de dominio. Esto permitirá liberar gran cantidad de tráfico inútil a su servidor web.
- Gracias a la implementación de Application Load Balancer obtendremos toda una gama de métricas de rendimiento que proporcionarán una visión mucho más detallada del tráfico que recibe nuestro sitio web. Desde el número de conexiones activas hasta volumetría de peticiones por clasificación (2xx, 3xx, 4xx, 5xx), tiempos de respuesta o incluso errores de negociación SSL.
- Application Load Balancer realiza comprobaciones de estado continuas para evaluar el estado del servicio en nuestro servidor web.
- Opcionalmente, Application Load Balancer permite generar un log de acceso detallado en S3, lo que habilita su explotación con herramientas de analítica avanzada como Amazon Athena o Quicksight.
- AWS Systems Manager (SSM) se integra con AWS Cloudtrail para la auditoría de acciones tales como el inicio y cierre de sesiones administrativas.
- Opcionalmente, el servicio permite generar una auditoría completa en Cloudwatch Logs con las acciones realizadas dentro de cada una de las sesiones, lo que permite incluso elevar alarmas en caso de detectarse que alguien ha ejecutado alguna acción especialmente sensible si esto fuera necesario.
- SSM También se integra con AWS IAM para el control granular de qué usuarios disponen de permisos para iniciar sesiones en nuestro servidor, todo ello sin necesidad de manipular la configuración de este.
- Application Load Balancer permite implementar rápidamente descarga de SSL, delegando todo el trabajo de encriptación de conexiones de cliente sobre el balanceador de carga y liberando por tanto a nuestro servidor, liberando capacidad para otras tareas de mayor utilidad.
AWS WAF. Un paso más en la seguridad
A pesar de haber conseguido reducir significativamente la superficie de ataque con la implementación de redes privadas, muchos atacantes pueden explotar vulnerabilidades de su sitio web en capa de aplicación, sobre todo si se trata de un CMS estándar bien conocido como WordPress.Para ayudar a mitigar este tipo de ataques, AWS ofrece su propio servicio de WAF, que se integra con Application Load Balancer para evaluar las reglas de seguridad antes de que el tráfico llegue a su servidor: AWS proporciona numerosos grupos de reglas para implementar fácilmente protecciones ante las principales amenazas del momento, pero existen también grupos de reglas de fabricantes especializados como F5 o Fortigate, o incluso pueden implementarse reglas completamente personalizadas. A continuación detallaremos los grupos de reglas suministrados directamente por AWS con aplicación directa en cualquier instalación de WordPress:
AWS proporciona numerosos grupos de reglas para implementar fácilmente protecciones ante las principales amenazas del momento, pero existen también grupos de reglas de fabricantes especializados como F5 o Fortigate, o incluso pueden implementarse reglas completamente personalizadas. A continuación detallaremos los grupos de reglas suministrados directamente por AWS con aplicación directa en cualquier instalación de WordPress:- AWSManagedRulesCommonRuleSet. Este grupo contiene reglas que son generalmente aplicables a cualquier aplicación web. Esto ofrece protección contra la explotación de una amplia gama de vulnerabilidades, como las de alto riesgo y más comunes descritas en publicaciones de OWASP como Top 10.
- AWSManagedRulesSQLiRuleSet. Este grupo contiene reglas para bloquear los patrones de solicitud asociados a la explotación de bases de datos SQL, como los ataques de inyección de código SQL. Este puede ayudar a evitar la inyección remota de consultas no autorizadas.
- AWSManagedRulesLinuxRuleSet. Este grupo contiene reglas que bloquean los patrones de solicitud asociados a la explotación de vulnerabilidades específicas de Linux, como los ataques de inclusión de archivos locales (LFI) específicos de Linux. Esto puede ayudar a evitar ataques que expongan el contenido de un archivos o ejecuten código que, en principio, tendría que ser inaccesible para los atacantes.
- AWSManagedRulesPHPRuleSet. Este grupo contiene reglas que bloquean los patrones de solicitud asociados a la explotación de vulnerabilidades específicas para el uso del lenguaje de programación PHP, como la inyección de funciones PHP poco seguras. Esto puede ayudar a evitar la explotación de vulnerabilidades que permiten a un atacante ejecutar de forma remota código o comandos sin autorización.
- AWSManagedRulesWordPressRuleSet. Este grupo de reglas contiene reglas que bloquean los patrones de solicitud asociados a la explotación de vulnerabilidades específicas de los sitios de WordPress.
Alta disponibilidad, siempre on air
En este punto nuestro sitio web cuenta con un grado de protección significativa, hemos mejorado sustancialmente la monitorización y tenemos aislada la base de datos de nuestro servidor web para facilitar su mantenimiento y operación. Sin embargo, el sistema sigue sufriendo cortes de servicio cada vez que se realiza cualquier operación de TI o cuando nuestros servidores sufren algún tipo de incidencia; para reducir el tiempo que nuestro sitio web está indisponible durante estas eventualidades, dotaremos a nuestra arquitectura de características de alta disponibilidad haciendo uso de múltiples zonas de disponibilidad de AWS y las características incluidas en los servicios gestionados incorporados hasta ahora. El principal cambio en este diseño es la provisión de un servidor web adicional (podrían ser más, tantos como creamos conveniente) detrás de nuestro balanceador de carga. Este servidor adicional reside en una zona de disponibilidad alternativa para mayor seguridad, y comparte con el servidor inicial tanto la base de datos RDS como una carpeta compartida NFS hospedada en un sistema de ficheros regional (replicado en múltiples AZs) de Elastic File System. Por simplicidad, en esta arquitectura la carpeta compartida contendrá todo el document_root del servidor web, lo que incluye tanto el core de WordPress como plugin, temas y la biblioteca de medios; esto permite minimizar el impacto operacional sobre las acciones del panel de WordPress que puede tener el compartir únicamente una subcarpeta.En el caso de la base de datos, para dotar de alta disponibilidad basta con activar la opción de despliegue Multi-AZ en nuestra instancia RDS. Esto desplegará automáticamente una réplica de lectura oculta en una zona de disponibilidad alternativa. En caso de fallo en la instancia primaria, AWS se encarga de ejecutar automáticamente el procedimiento de failover consistente en promocionar la réplica de lectura a maestro y modificar el DNS para apuntar a la “ex-réplica”. Asimismo, cada vez que se requiera ejecutar acciones de TI como parcheo, redimensionamientos o reconfiguraciones con reinicio obligatorio de la instancia, Amazon RDS aplicará los cambios primero en la réplica para seguidamente realizar un failover y finalmente poder operar sobre la instancia restante. Todo con un corte de servicio de unos pocos segundos.Por su parte, Application Load Balancer se trata de un servicio inherentemente altamente disponible y no permite ser desplegado en una única zona de disponibilidad con lo que no es necesaria ninguna acción.En cuanto a la pasarela de NAT, cada instancia de NAT Gateway es altamente disponible dentro de su zona de disponibilidad. En caso de fallo global en una zona de disponibilidad dejaríamos sin servicio a toda la plataforma de servidores, con lo que es recomendable que las subredes privadas de cada AZ hagan uso de una NAT Gateway dedicada.Con todos estos cambios implementados, ninguna pieza de nuestra infraestructura supone un punto único de fallo. Todos los componentes están replicados en zonas de disponibilidad separadas y la arquitectura es lo suficientemente resiliente como para soportar el fallo de toda una zona de disponibilidad de la región donde hospedemos nuestra plataforma.La contraprestación más destacable en este caso es el significativo aumento de costes, ya que respecto del diseño del apartado 4 prácticamente habremos duplicado el coste de la plataforma. Adicionalmente, se nos presenta la necesidad de administrar múltiples servidores web, lo que aumentará la carga de trabajo de los operadores y podría redundar en problemas de inconsistencia si no se tiene un control riguroso o automatizado de la configuración de estos. Para estos casos, siempre recomendamos hacer uso de sistemas de gestión de la configuración como Puppet, Ansible o Chef y evitar la administración manual de cualquier servidor.
El principal cambio en este diseño es la provisión de un servidor web adicional (podrían ser más, tantos como creamos conveniente) detrás de nuestro balanceador de carga. Este servidor adicional reside en una zona de disponibilidad alternativa para mayor seguridad, y comparte con el servidor inicial tanto la base de datos RDS como una carpeta compartida NFS hospedada en un sistema de ficheros regional (replicado en múltiples AZs) de Elastic File System. Por simplicidad, en esta arquitectura la carpeta compartida contendrá todo el document_root del servidor web, lo que incluye tanto el core de WordPress como plugin, temas y la biblioteca de medios; esto permite minimizar el impacto operacional sobre las acciones del panel de WordPress que puede tener el compartir únicamente una subcarpeta.En el caso de la base de datos, para dotar de alta disponibilidad basta con activar la opción de despliegue Multi-AZ en nuestra instancia RDS. Esto desplegará automáticamente una réplica de lectura oculta en una zona de disponibilidad alternativa. En caso de fallo en la instancia primaria, AWS se encarga de ejecutar automáticamente el procedimiento de failover consistente en promocionar la réplica de lectura a maestro y modificar el DNS para apuntar a la “ex-réplica”. Asimismo, cada vez que se requiera ejecutar acciones de TI como parcheo, redimensionamientos o reconfiguraciones con reinicio obligatorio de la instancia, Amazon RDS aplicará los cambios primero en la réplica para seguidamente realizar un failover y finalmente poder operar sobre la instancia restante. Todo con un corte de servicio de unos pocos segundos.Por su parte, Application Load Balancer se trata de un servicio inherentemente altamente disponible y no permite ser desplegado en una única zona de disponibilidad con lo que no es necesaria ninguna acción.En cuanto a la pasarela de NAT, cada instancia de NAT Gateway es altamente disponible dentro de su zona de disponibilidad. En caso de fallo global en una zona de disponibilidad dejaríamos sin servicio a toda la plataforma de servidores, con lo que es recomendable que las subredes privadas de cada AZ hagan uso de una NAT Gateway dedicada.Con todos estos cambios implementados, ninguna pieza de nuestra infraestructura supone un punto único de fallo. Todos los componentes están replicados en zonas de disponibilidad separadas y la arquitectura es lo suficientemente resiliente como para soportar el fallo de toda una zona de disponibilidad de la región donde hospedemos nuestra plataforma.La contraprestación más destacable en este caso es el significativo aumento de costes, ya que respecto del diseño del apartado 4 prácticamente habremos duplicado el coste de la plataforma. Adicionalmente, se nos presenta la necesidad de administrar múltiples servidores web, lo que aumentará la carga de trabajo de los operadores y podría redundar en problemas de inconsistencia si no se tiene un control riguroso o automatizado de la configuración de estos. Para estos casos, siempre recomendamos hacer uso de sistemas de gestión de la configuración como Puppet, Ansible o Chef y evitar la administración manual de cualquier servidor.Autoscaling. Un equilibrio entre operación y negocio
Ahora que nuestro sistema cuenta con alta disponibilidad es cuando podemos concentrarnos en resolver el problema de la escalabilidad del servicio. A medida que nuestro sitio web crezca en popularidad observaremos cómo la base de datos y nuestros servidores web sufren en algún momento problemas de capacidad que deberemos resolver a la mayor brevedad para tratar de no incurrir en cortes de servicio.En el caso de la base de datos, al estar implementada sobre RDS MultiAZ tenemos múltiples opciones para resolver este problema:- Redimensionamientos verticales. Al contar con una implementación MultiAZ, estos procesos tienen un impacto mínimo en el servicio aunque es necesario lanzarlos de forma manual o semiautomatizada.
- Adición de hasta 5 réplicas de lectura. Tanto para MySQL como MariaDB, Amazon RDS habilita la implementación rápida de hasta 5 réplicas de lectura, permitiendo así repartir la carga de consultas entre las distintas réplicas. Sin embargo, la adición o eliminación de réplicas suele implicar modificaciones en los servidores web para que se adapten al cambio.
- Auto escalado de réplicas de lectura con Amazon Aurora. 100% compatible con MySQL 5.6 o MySQL 5.7, Amazon ofrece este motor a sus clientes para implementar clúster con hasta 16 réplicas de lectura con bajo lag de replicación y escalado automático. Esta opción, aunque de mayor coste por instancia, es la que permite adaptar mejor la capacidad contratada a la demanda real cuando la demanda sea impredecible o el negocio tenga unos rangos de variabilidad de tráfico muy amplios mediante la adición o retirada de réplicas de lectura en función del uso de recursos global del clúster. RDS Aurora proporciona puntos de enlace estáticos para escritura y lectura, donde el punto de enlace de escritura apunta siempre al nodo primario en cada momento y el punto de enlace de lectura reparte carga entre las distintas réplicas que en cada momento esté presente.
- Lanzar o terminar instancias según requiera la demanda, utilizando para ello la métrica de rendimiento de nuestra elección y un umbral de utilización objetivo.
- Añadir las nuevas instancias EC2 a nuestro balanceador de carga y drenar las conexiones pendientes durante los procesos de terminación de estas.
- Reemplazar automáticamente instancias EC2 que tengan fallos en la comprobación de estado del balanceador de carga.
- Opcionalmente, contratar las nuevas instancias en modalidad Spot para reducir hasta un 90% los costes operativos del cómputo.
- Opcionalmente, diversificar los tipos de instancia contratados para garantizar la capacidad y reducir los costes operativos
- Recolectar métricas de rendimiento agrupadas (EC2, tráfico de red, volumetría de máquinas, etc.)
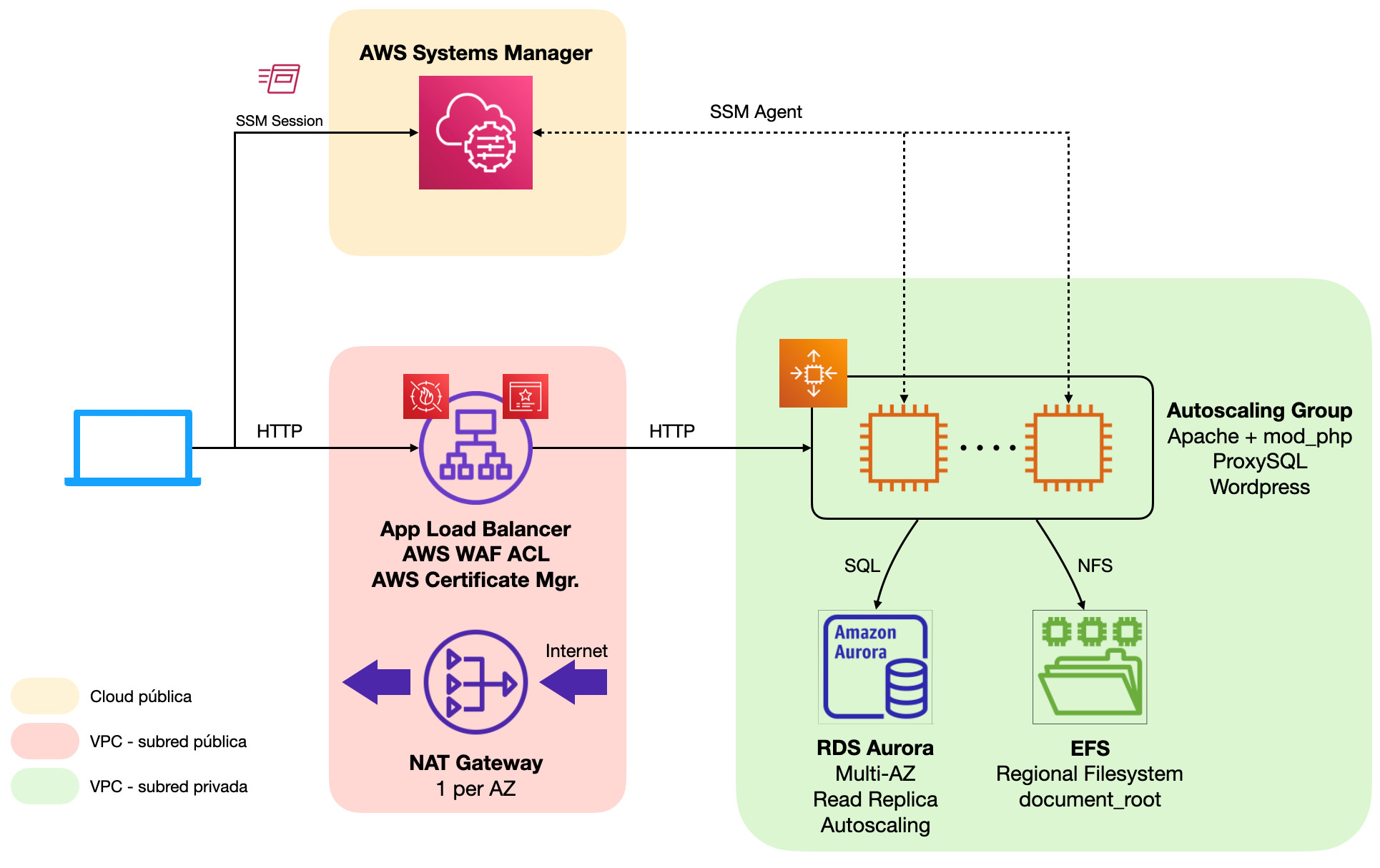 El resto de los servicios de nuestra plataforma (Application Load Balancer, NAT Gateway, EFS…) son inherentemente escalables y no necesitan acciones concretas.Es altamente recomendable tener un procedimiento lo más automatizado posible para el mantenimiento de las plantillas de despliegue de instancias EC2, ya que la aplicación de cambios y parches de seguridad en nuestros servidores pasará a partir de este momento por la creación de una nueva plantilla de despliegue y rotar todos los servidores activos en un momento dado. Herramientas como Hashicorp Packer o EC2 Image Builder en combinación con servicios de CI/CD son ideales para este fin.Este cambio tiene un impacto muy significativo en la operación de nuestros servidores web y en un primer momento puede resultar difícil adoptar el cambio por parte de los operadores, pero una vez en marcha, los beneficios económicos y la estabilidad de la plataforma ante picos de demanda o incluso ante fallos operacionales puntuales justifican con creces el cambio. Si además se consigue implementar con éxito pipelines para la construcción automatizada de imágenes y plantilla de lanzamiento, rápidamente será evidente la ganancia en términos de agilidad operacional.
El resto de los servicios de nuestra plataforma (Application Load Balancer, NAT Gateway, EFS…) son inherentemente escalables y no necesitan acciones concretas.Es altamente recomendable tener un procedimiento lo más automatizado posible para el mantenimiento de las plantillas de despliegue de instancias EC2, ya que la aplicación de cambios y parches de seguridad en nuestros servidores pasará a partir de este momento por la creación de una nueva plantilla de despliegue y rotar todos los servidores activos en un momento dado. Herramientas como Hashicorp Packer o EC2 Image Builder en combinación con servicios de CI/CD son ideales para este fin.Este cambio tiene un impacto muy significativo en la operación de nuestros servidores web y en un primer momento puede resultar difícil adoptar el cambio por parte de los operadores, pero una vez en marcha, los beneficios económicos y la estabilidad de la plataforma ante picos de demanda o incluso ante fallos operacionales puntuales justifican con creces el cambio. Si además se consigue implementar con éxito pipelines para la construcción automatizada de imágenes y plantilla de lanzamiento, rápidamente será evidente la ganancia en términos de agilidad operacional.Cache compartida y CDN. Optimizando la arquitectura
Hasta ahora todos los esfuerzos de arquitectura los hemos realizado con dos objetivos claros: continuidad del servicio y seguridad. Sin embargo, no nos hemos centrado en una de las principales preocupaciones de los administradores de sitios web: el rendimiento y la experiencia de usuario (UX), claves para atraer el mayor número de visitas y maximizar la satisfacción del cliente.En este artículo nos centraremos en la implementación del plugin W3 Total Cache de WordPress y su integración con distintos servicios gestionados de Amazon Web Services. Este plugin, en su capa gratuita, permite implementar múltiples opciones de cache y rendimiento, entre las que destacaremos:- Cachés de páginas, objetos y queries de base de datos. Gracias a estas opciones podremos reducir muy significativamente el tiempo de respuesta de nuestro sitio web. Por norma general, es de esperar un speedup en torno al 75%.
- Integración con servicios populares de distribución de contenidos (CDN), entre los que se encuentra Amazon Cloudfront

NOTA: Hoy en día no existe una opción de auto escalado de nodos para clúster compatibles con Memcached. Sin embargo, en infraestructuras WordPress raramente tendremos la necesidad de modificar nuestro clúster de Memcached dado el altísimo rendimiento por CPU de Memcached y lo acotado del tamaño máximo de los contenidos cacheados en WordPress.
En lo que respecta al CDN, W3 Total Cache se encarga de generar URLs personalizadas para todos los contenidos estáticos de nuestro sitio WordPress, tanto de nuestros temas como de la biblioteca de contenidos, reemplazando automáticamente el dominio principal de WordPress por el de nuestra distribución Cloudfront.NOTA: Hoy en día W3 Total Cache no es compatible con roles de IAM con lo que es obligatorio gestionar usuarios de IAM con claves de API estáticas si se quiere hacer uso de las opciones de provisión e invalidación de contenidos automática con distribuciones de Cloudfront.
Una vez implementado el servicio de CDN, todo el contenido estático de nuestro sitio web se cacheará en las ubicaciones de borde de la red global de AWS Cloudfront, reduciendo significativamente la latencia de descarga desde los navegadores de los usuarios, redundando con ello en una mejora en la experiencia de usuario muy significativa así como una descarga de carga en los servidores web, que únicamente necesitan servir peticiones en caso de fallos en la caché de alguno de los nodos de borde. Las tasas de acierto en caché en cualquier sitio web WordPress tienen a ser mu altas (por lo general superiores al 95%) con lo que podemos considerar residual la carga de trabajo que supone la entrega de contenido estático en nuestros servidores web.Con la introducción de estos nuevos componentes la arquitectura quedaría como en el siguiente diagrama: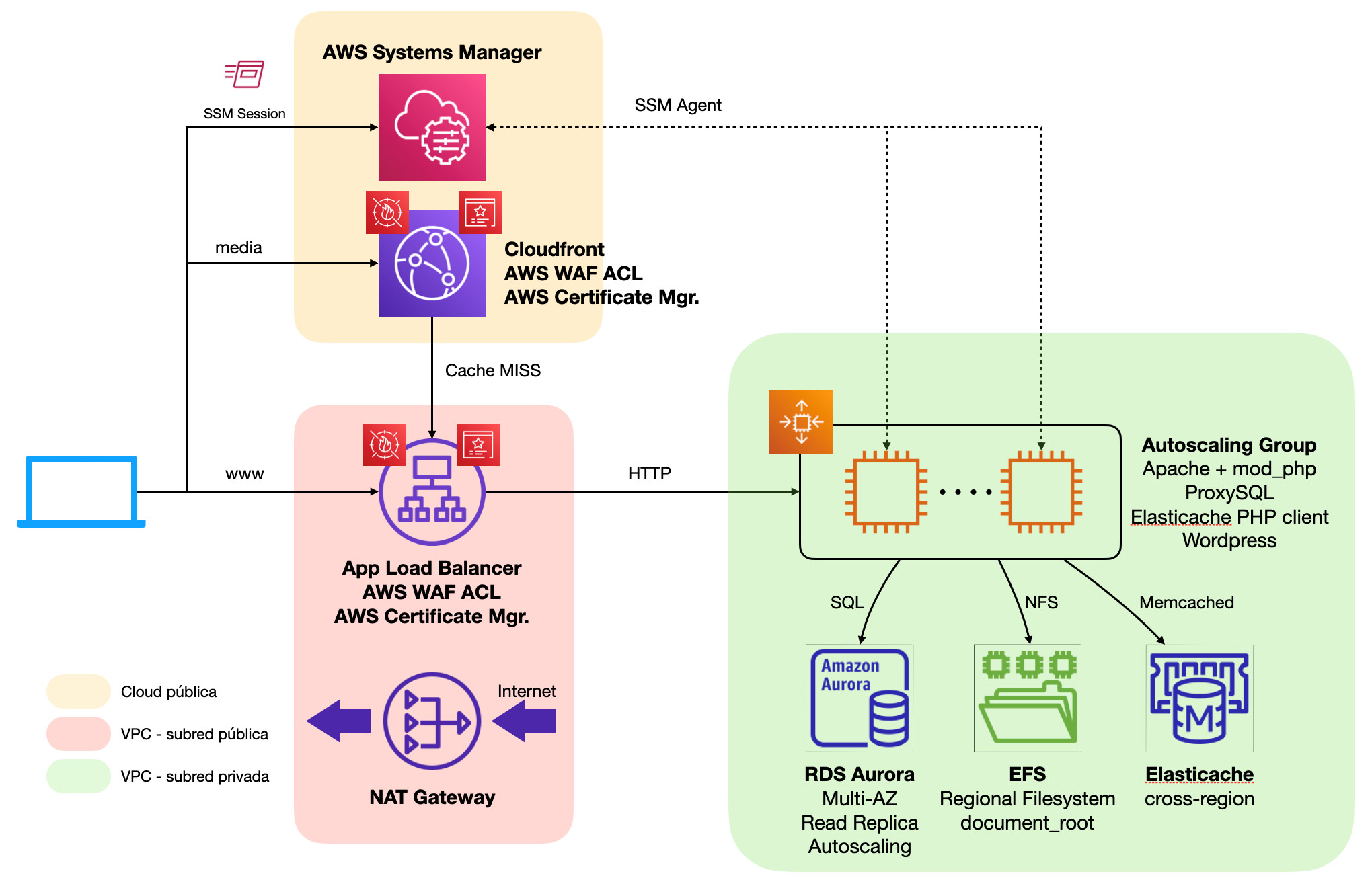 Como contraprestaciones en este caso tendríamos dos:Por un lado, la introducción de sistemas de cacheo puede dificultar en ciertos momentos la gestión de contenidos. Es habitual que administradores no experimentados en el uso de este tipo de sistemas piensen que sus cambios no tienen ningún efecto en el frontend, cuando realmente lo único que hay que hacer es lanzar un proceso de vaciado de cachés para que sus cambios se propaguenEn segundo lugar, el potencial incremento de costes de infraestructura debido a la adición de nuevos componentes. Sin embargo, gracias a la descarga de trabajo para la entrega de contenido estático y la significativa mejora de rendimiento en el renderizado de PHP por la introducción de múltiples sistemas de cacheo de contenido redundarán en una menor utilización de recursos tanto en los servidores web como en la base de datos, las piezas de mayor coste de toda la plataforma, con lo que es de esperar no solo una mejora de rendimiento sino incluso una reducción de costes por el menor uso de capacidad en los componentes principales.
Como contraprestaciones en este caso tendríamos dos:Por un lado, la introducción de sistemas de cacheo puede dificultar en ciertos momentos la gestión de contenidos. Es habitual que administradores no experimentados en el uso de este tipo de sistemas piensen que sus cambios no tienen ningún efecto en el frontend, cuando realmente lo único que hay que hacer es lanzar un proceso de vaciado de cachés para que sus cambios se propaguenEn segundo lugar, el potencial incremento de costes de infraestructura debido a la adición de nuevos componentes. Sin embargo, gracias a la descarga de trabajo para la entrega de contenido estático y la significativa mejora de rendimiento en el renderizado de PHP por la introducción de múltiples sistemas de cacheo de contenido redundarán en una menor utilización de recursos tanto en los servidores web como en la base de datos, las piezas de mayor coste de toda la plataforma, con lo que es de esperar no solo una mejora de rendimiento sino incluso una reducción de costes por el menor uso de capacidad en los componentes principales.Infraestructura de contenedores serverless
Si nuestro sitio web ha generado la suficiente popularidad como para demandar una infraestructura de tantas garantías como la del apartado 7, lo más probable es que ya dispongamos de un equipo de desarrollo solvente con un proceso de desarrollo estandarizado en el que el control de versiones del core de WordPress, plugin y temas sea mucho más férreo respecto de lo que es habitual en un sitio de menor tamaño, donde los administradores tienen acceso completo a todas las opciones de actualización y gestión de plugin o temas.Para minimizar riesgos entre la fase desarrollo y la puesta en producción de cambios el paradigma óptimo son los contenedores. El uso de esta tecnología permite a los desarrolladores validar sus cambios de forma local minimizando los riesgos derivados de inconsistencias entre los entornos de servidores en AWS y sus puestos de desarrollo.El principal impacto que va a tener este cambio es que los contenedores de WordPress ya no van a compartir el document_root completo desde EFS; sino únicamente lo que suponen realmente datos, en este caso:- La carpeta wp-content/uploads donde se almacena la biblioteca de medios de WordPress
- La carpeta wp-content/w3tc-config donde se almacenan las configuraciones persistentes del plugin W3 Total Cache.
- Registro de Elastic Container Registry para almacenar las imágenes personalizadas
- Clúster Elastic Container Service (ECS) para orquestar la provisión, monitorización y configuración de contenedores.
- Dentro de este clúster desplegaremos un servicio de tipo Fargate con integración en Application Load Balancer, que reemplazará a nuestro clúster de EC2 Autoscaling.
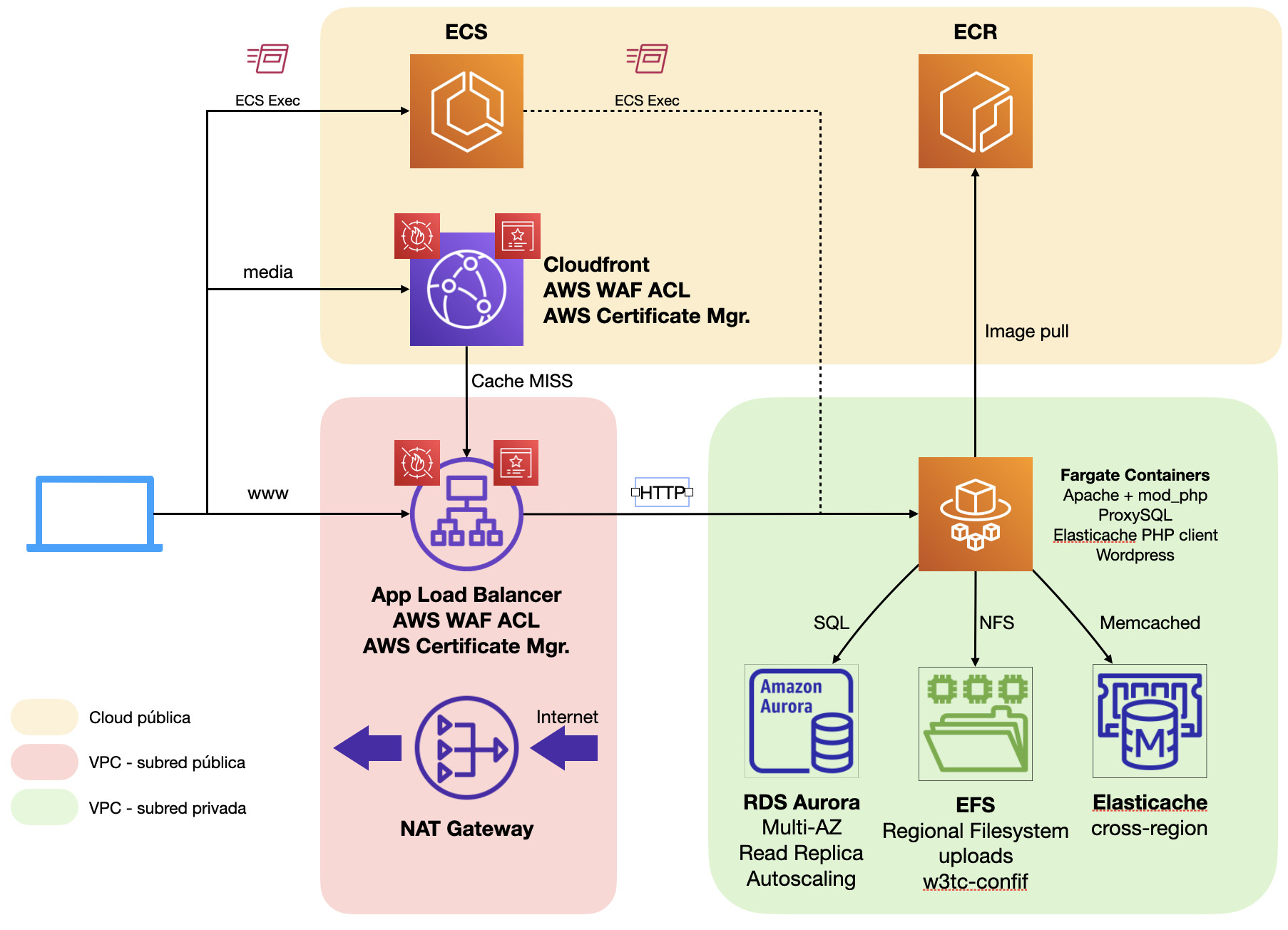 El uso de AWS Fargate implica además que no necesitamos provisionar instancias EC2 en nuestro clúster de ECS. Amazon se encarga de gestionar la infraestructura de ejecución de contenedores y solo pagamos por la CPU y memoria que utilicen nuestros contenedores. Esto hace que ya no necesitemos administrar imágenes de instancia periódicamente ni preocuparnos por el parcheado de servidores, ya que estas tareas pasan a estar gestionadas por AWS.La contraprestación de este cambio es la impedancia de entrada que supone el cambio de paradigma. Para aquellos administradores y desarrolladores acostumbrados a la forma “clásica” de trabajo, el cambio a contenedores puede suponerles una dificultad añadida para desempeñar su trabajo. Sin embargo, las garantías de consistencia en los despliegues, la agilidad que toma el proceso de desarrollo y la facilidad para replicar entornos suelen justificar sobradamente el cambio.
El uso de AWS Fargate implica además que no necesitamos provisionar instancias EC2 en nuestro clúster de ECS. Amazon se encarga de gestionar la infraestructura de ejecución de contenedores y solo pagamos por la CPU y memoria que utilicen nuestros contenedores. Esto hace que ya no necesitemos administrar imágenes de instancia periódicamente ni preocuparnos por el parcheado de servidores, ya que estas tareas pasan a estar gestionadas por AWS.La contraprestación de este cambio es la impedancia de entrada que supone el cambio de paradigma. Para aquellos administradores y desarrolladores acostumbrados a la forma “clásica” de trabajo, el cambio a contenedores puede suponerles una dificultad añadida para desempeñar su trabajo. Sin embargo, las garantías de consistencia en los despliegues, la agilidad que toma el proceso de desarrollo y la facilidad para replicar entornos suelen justificar sobradamente el cambio.



