
- abril 1, 2026
- 0 Comments
- By Aleyna Tomris

Miguel Ángel Tomé
Introducción
La infraestructura digital es hoy el eje crítico de cualquier servicio de negocio, y en 2026, la resiliencia no es opcional: es un requisito estándar. Los sistemas modernos deben soportar fallos de hardware, saturación de recursos, desastres naturales o ataques sofisticados sin interrumpir la continuidad operativa. Para ello, las arquitecturas deben ser capaces de autocorregirse, redistribuir cargas de manera inteligente, anticipar fallos y ejecutar planes de contingencia automáticamente.
El desafío reside en integrar múltiples capas: cloud híbrido, multicloud federado, edge computing, serverless crítico y AIOps predictivo, garantizando que aplicaciones de misión crítica mantengan disponibilidad, consistencia y cumplimiento de SLOs, incluso frente a fallos simultáneos en distintas regiones. La combinación de autosanación, multicloud, observabilidad predictiva y seguridad zero-trust redefine cómo se entrega resiliencia extrema.
Redundancia Multinivel y Topologías Autónomas
Redundancia a nivel de Zona de Disponibilidad (AZ-aware Design)
En 2026, la replicación de datos entre AZs es solo el primer paso; lo crítico es que cada componente sea consciente de su ubicación relativa y de los recursos circundantes. La infraestructura distribuye instancias de manera automática usando algoritmos de placement que consideran latencia interna, saturación de CPU/memoria y afinidad de red, asegurando que el fallo de una AZ no comprometa el servicio.
Los sistemas de almacenamiento implementan replicación multi-AZ con consistencia configurable, permitiendo operaciones críticas con strong consistency mientras se usan modos eventual para datos secundarios. El balanceo predictivo se basa en telemetría de saturación y algoritmos de machine learning, moviendo cargas antes de que se produzcan cuellos de botella. Esto elimina los points of failure y maximiza la continuidad de negocio.
Arquitecturas Activo-Activo Regionales
El modelo activo-activo permite que múltiples regiones procesen transacciones simultáneamente sin sacrificar consistencia. Protocolos avanzados como Calvin, Raft híbrido o Spanner-style consensus coordinan escrituras entre regiones para mantener integridad y permitir RPO cercano a cero. La replicación near real-time asegura que los datos críticos se reflejen en milisegundos, y los routers globales redirigen tráfico automáticamente hacia la región más saludable, garantizando un RTO mínimo. Este modelo es esencial en servicios financieros, IoT industrial y plataformas globales de e-commerce.
Topologías Globales Autónomas (Self-Adaptive Topologies)
En lugar de topologías estáticas, las topologías autónomas ajustan rutas y distribución de cargas según telemetría en tiempo real. Algoritmos ML optimizan la colocación de instancias, minimizando latencia y balanceando carga geográficamente. Además, estas topologías anticipan riesgos operacionales, redistribuyendo recursos ante fallos parciales o saturación de proveedores. La combinación de IA con reglas de negocio permite resiliencia proactiva y optimización continua de costes y rendimiento.
Arquitecturas Autosanables (Self-Healing Systems)
Remediación Proactiva Basada en ML
La autosanación de 2026 anticipa fallos en lugar de reaccionar. Modelos de ML analizan series temporales de CPU, memoria, IOPS y logs para identificar patrones de degradación. Con base en estas predicciones, la infraestructura rebalancea cargas y reemplaza nodos críticos antes de que ocurran fallos, manteniendo estabilidad y continuidad de servicio.
Reconstrucción Declarativa con IaC Avanzado
La infraestructura se gestiona mediante IaC declarativa, utilizando GitOps transaccional y plantillas inmutables que regeneran clústeres completos de forma reproducible. Las políticas como código (Policy as Code) garantizan cumplimiento normativo y límites de recursos, integrando seguridad y resiliencia en cada despliegue.
Alineación con Objetivos SRE (SLO-driven Healing)
Los mecanismos de autosanación solo se activan cuando se comprometen SLOs de latencia, error rate o saturación, evitando sobre-reacción y manteniendo estabilidad del sistema. Esto asegura que la corrección sea efectiva, segura y priorizada según impacto real en servicio.
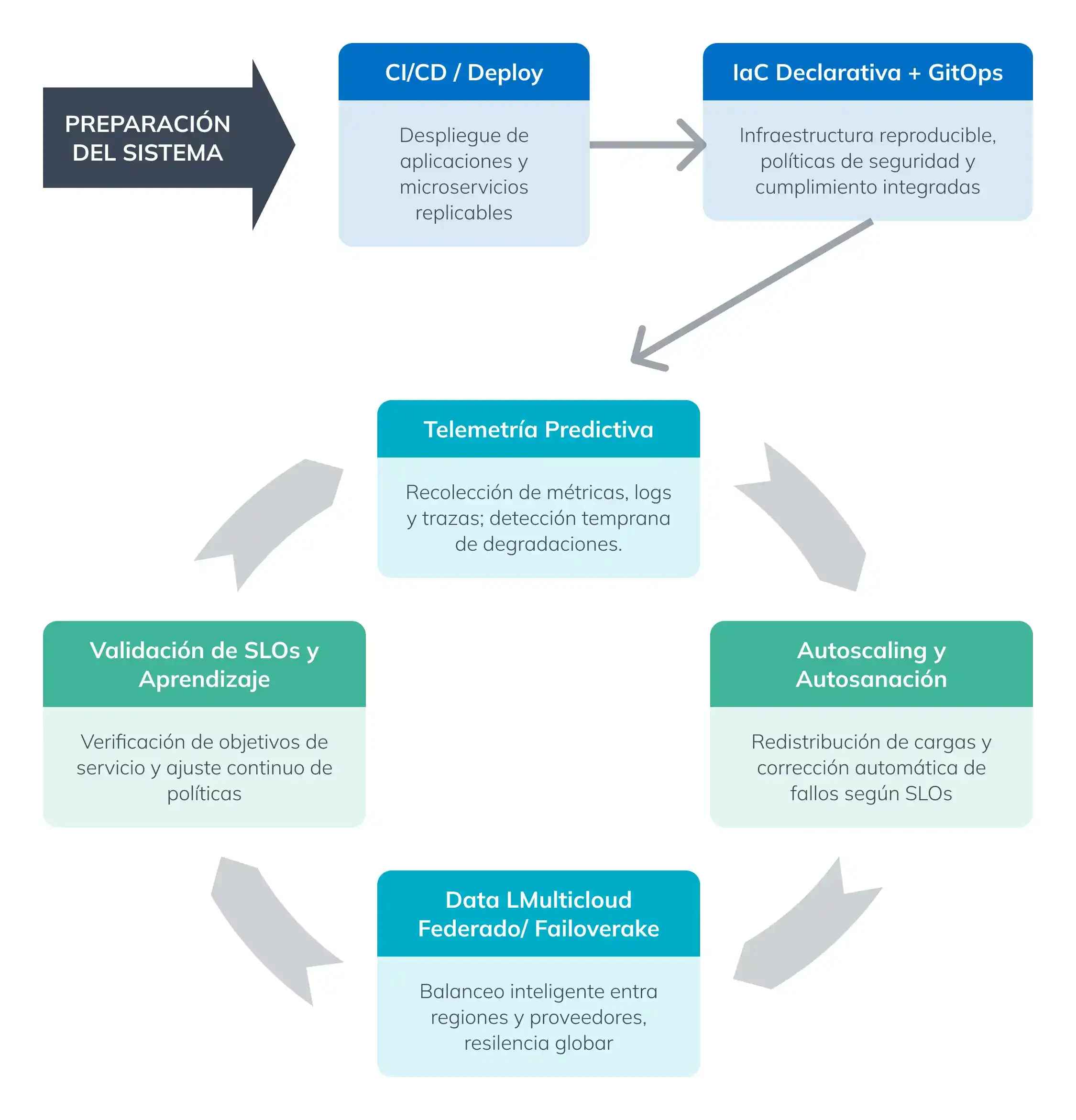
Flujo de resiliencia y autosanación de la infraestructura 2026
Este flujo muestra cómo los sistemas modernos garantizan resiliencia y disponibilidad extrema mediante un ciclo continuo de despliegue, observación, corrección y validación. Cada etapa del flujo transforma datos y acciones en decisiones automatizadas, asegurando que los servicios críticos se mantengan activos y cumpliendo sus objetivos de servicio (SLOs). El Feedback Loop permite aprender de cada evento y mejorar continuamente la predicción y la respuesta de la infraestructura.
Pipeline de resiliencia autónoma y autosanación 2026
Multicloud Federado
Federaciones de Clústeres Kubernetes
En 2026, el multicloud es requisito de resiliencia. Las federaciones sincronizan políticas y workloads entre proveedores, usando service mesh federado para failover transparente y balanceo inteligente de tráfico. Los despliegues se gestionan con GitOps multi-cluster, garantizando consistencia y reproducibilidad en todos los entornos.
Enrutamiento Global Inteligente
Motores de routing global seleccionan la región óptima según latencia, saturación y disponibilidad, aplicando weighted routing y circuit breaking para evitar propagación de fallos. Esto permite una resiliencia real sin intervención manual.
Datos Multicloud Consistentes
Bases de datos multicloud utilizan CRDTs, multi-leader replication y relojes híbridos para mantener coherencia en datos críticos, garantizando consistencia eventual eficiente y minimizando latencia inter-cloud. La sincronización optimizada balancea consistencia, disponibilidad y costes.
Observabilidad Predictiva y AIOps
Telemetry as Code (TaC)
Cada componente define métricas, logs estructurados y trazas como parte del pipeline CI/CD. OpenTelemetry y Prometheus permiten correlar trazas y metadatos extendidos, creando un grafo de dependencias en tiempo real que anticipa degradaciones y cuellos de botella antes de afectar usuarios.
Detección de Anomalías Multidimensional
Modelos ML correlacionan latencia, saturación, errores y logs, detectando degradaciones invisibles para la observabilidad clásica. Técnicas de clustering, análisis de series temporales y detección de outliers identifican riesgos críticos antes de impactar producción.
Autoscaling Predictivo
Escalado basado en predicción de picos usando series temporales o redes neuronales recurrentes (LSTM), con balanceo dinámico y ajuste de recursos previo a la saturación, evitando degradación de servicio incluso en campañas de alto tráfico.
Seguridad Zero-Trust Integrada
Segmentación Dinámica y Aislamiento
Microsegmentación con mTLS obligatorio, rotación automática de claves y políticas centradas en servicios aseguran aislamiento granular y control total del flujo de datos, reduciendo riesgos de movimiento lateral en la infraestructura.
Redundancia de Identidad
Identity Providers replicados activamente entre regiones, con caches criptográficos y certificados revocables distribuidos, permiten autenticación continua incluso en entornos aislados o ante fallos de conectividad interregional.
Backups Inmutables
Snapshots inmutables con hashes criptográficos y recuperación automatizada validada por IA aseguran integridad y cumplimiento regulatorio, protegiendo frente a ransomware o corrupción de datos.
Serverless Crítico y Eventos Resilientes
Funciones Replicadas y Failover
Serverless replicado intra y multi-región con coordinación activa garantiza continuidad de cargas críticas y failover automático transparente. La ejecución se sincroniza para evitar duplicidad de resultados.
Colas y Streams
Persistencia distribuida triple y entrega better-than-once, con enrutamiento cross-cloud que valida estados y aplica compensaciones inteligentes, asegurando consistencia predictiva incluso ante fallos parciales.
Ingeniería del Caos Avanzada
La ingeniería del caos moderno no se limita a desconectar servicios de manera aleatoria; en 2026 es un proceso controlado, predictivo y basado en SLOs, que prueba la resiliencia de sistemas distribuidos complejos antes de que los fallos reales ocurran.
Simulación de fallos complejos y multidimensionales
- Se generan escenarios que incluyen desconexión total de regiones, fallos simultáneos de AZs, latencia artificial extrema, pérdida de paquetes y degradación de recursos de almacenamiento.
- Las simulaciones incluyen tanto componentes de infraestructura (nodos, bases de datos, colas) como servicios aplicacionales (microservicios críticos, pipelines serverless).
- Se aplican técnicas de inyección de fallo controlada usando frameworks como Chaos Mesh, Gremlin o Litmus, que interactúan directamente con las APIs de orquestación (Kubernetes, serverless o IaC).
Chaos programado basado en SLOs
- Las pruebas no se ejecutan de manera aleatoria, sino que se planifican considerando los SLOs de latencia, error rate y disponibilidad.
- Los algoritmos priorizan los experimentos sobre servicios secundarios primero y expanden gradualmente a componentes críticos, garantizando que el usuario final no experimente interrupciones.
- Se calculan métricas clave durante la prueba:
- Elasticidad: capacidad de escalar automáticamente frente a un fallo.
- Tiempo de convergencia de autosanación: cuánto tarda el sistema en volver a estado óptimo.
- Capacidad de recuperación ante fallos múltiples: porcentaje de servicios que mantienen disponibilidad total durante fallos simultáneos.
Integración con Observabilidad Predictiva
- Cada experimento de caos se registra con telemetría estructurada, trazas OpenTelemetry y logs enriquecidos.
- Los sistemas de AIOps analizan el comportamiento del sistema bajo fallo y refinan modelos de predicción, mejorando la capacidad de detectar degradaciones antes de que ocurran.
Aprendizaje continuo
- Los resultados de cada simulación alimentan algoritmos de machine learning que ajustan automáticamente las políticas de autosanación, autoscaling y failover.
- Esto convierte la resiliencia en un proceso adaptativo y continuo, no en un conjunto estático de reglas.
Orquestación Autónoma de DRP (Disaster Recovery Plan)
El DRP autónomo en 2026 es un sistema automatizado, seguro y predictivo, diseñado para garantizar continuidad incluso en escenarios catastróficos. Su funcionamiento combina IA, observabilidad avanzada y políticas de seguridad zero-trust:
Simulaciones periódicas y realistas
- Cada mes se ejecutan simulaciones completas de desastre que incluyen fallos simultáneos de regiones, pérdida de proveedores y corrupción de datos simulada.
- Estas simulaciones no afectan usuarios porque se ejecutan en entornos de staging que replican infraestructura de producción o mediante sandboxing de workloads críticos.
Automatización completa de recuperación
- Los workflows de DRP incluyen: restauración de bases de datos desde snapshots inmutables, reinicio de clusters multi-región, reconfiguración de redes y reubicación de workloads serverless.
- La infraestructura se auto-orquesta mediante IaC declarativa y GitOps transaccional, garantizando que la reconstrucción sea idéntica a producción y sin intervención manual.
Validación inteligente post-recuperación
- La IA analiza consistencia de datos, integridad de aplicaciones y cumplimiento de SLOs.
- Detecta cualquier divergencia en replicación de bases de datos, estado de colas o resultados de microservicios, corrigiendo automáticamente antes de reactivar tráfico a producción.
Integración con Observabilidad Predictiva y Seguridad Zero-Trust
- Durante la recuperación, todos los servicios aplican microsegmentación, políticas de identidad distribuidas y mTLS, asegurando que la seguridad no se vea comprometida incluso durante la recuperación.
- La telemetría continua permite detectar degradaciones durante el DRP y ajustar recursos de manera proactiva.
Auditoría y cumplimiento
- Cada DRP genera un registro completo, incluyendo acciones automatizadas, eventos de fallo simulados y resultados de validaciones.
- Esto permite cumplimiento regulatorio total (GDPR, SOC2, CCPA) y trazabilidad para auditorías internas y externas.
Conclusión
En 2026, la resiliencia es un componente integral del diseño de infraestructura. La combinación de autosanación, observabilidad predictiva, multicloud federado, serverless crítico y seguridad zero-trust convierte la alta disponibilidad extrema en estándar. Las plataformas modernas ya no solo sobreviven ante fallos múltiples: anticipan, corrigen y mantienen continuidad de negocio con mínima intervención humana, garantizando consistencia, cumplimiento y optimización de recursos.

