- noviembre 25, 2025
- 0 Comments
- By Elena

Javier García
Introducción
La gestión de parches es una práctica crítica en cualquier organización que busque mantenerse segura, eficiente y alineada con las normativas. Automatizar este proceso permite reducir la exposición a vulnerabilidades, mitigar riesgos operativos y garantizar continuidad de servicio con eficiencia operativa.
En esta guía técnica y profesional, exploraremos un enfoque completo para diseñar políticas robustas de parcheo automatizado, así como las herramientas de mercado más destacadas. Cubriremos el ciclo completo: desde el análisis de vulnerabilidades hasta la validación post-parcheo, sin perder el rigor necesario para ambientes corporativos.
¿Qué es la gestión de parches automatizada?
La gestión de parches automatizados consiste en implementar flujos programados que detectan, descargan, prueban, distribuyen e instalan parches en sistemas operativos, software de red, aplicaciones corporativas y dispositivos. Requiere:
- Inventario actualizado desde la CMDB.
- Orquestación de actualizaciones sin interacción manual.
- Validación post-parcheo y ejecución de misión crítica.
- Integración con procesos ITIL como Change Management y Security Management.
El objetivo es maximizar la seguridad sin comprometer la estabilidad operativa.
Beneficios estratégicos y riesgos mitigados
Las organizaciones obtienen:
- Reducción significativa de vulnerabilidades (seguridad proactiva).
- Cumplimiento normativo (PCI-DSS, HIPAA, ISO 27001).
- Menos esfuerzo manual y menores riesgos asociados a errores humanos.
- Mayor visibilidad y trazabilidad, gracias a logs y dashboards.
- Continuidad del servicio, evitando cuellos de botella manuales.
- Ahorro de recursos, al liberar técnicos para tareas críticas.
Componentes clave de una política efectiva
Una política de gestión de parches automatizada debe incluir:
- Alcance: sistemas, entornos, dispositivos y software.
- Riesgo tolerable: prioridad en parches críticos y seguridad.
- Frecuencia y calendarización: mensual, trimestral, urgente.
- Entornos de pruebas: se requiere una fase piloto antes del despliegue general.
- Tiempo de ejecución: horas definidas para mantenimiento (ventanas).
- Aprobaciones: revisión previa del cambio, registro en Change Management.
- Criterios de exclusión: sistemas legacy, entornos controlados.
- Rol y responsabilidad: quién programa, aprueba, verifica.
- Matriz de comunicación: equipos impactados, notificaciones y escalado.
- KPIs de cumplimiento: tasa de éxito, tiempo de parcheo, fallos.
Arquitectura y flujo del proceso
Una arquitectura integral debe contemplar:
- Descubrimiento de activos: CMDB, escaneo de red y dispositivos.
- Evaluación de vulnerabilidades: integración con proyectos como Qualys, Nessus, WSUS.
- Clasificación y priorización: de acuerdo a la criticidad, CVSS, impacto de negocio.
- Planificación y prueba: en entornos staging con rollback.
- Despliegue automatizado: mediante orquestación (RPA, scripts).
- Validación y remediación: validación y solución de errores.
- Reporte y trazabilidad: dashboard, logs, Change ticket.
- Mejora continua: análisis de resultados, lecciones aprendidas.
Selección de herramientas de parcheo
Las principales plataformas incluyen:
- Microsoft WSUS / SCCM / Intune: gestión de parches en Windows y Office.
- ManageEngine Patch Manager Plus: entornos mixtos (Windows, macOS, Linux).
- Ivanti Patch for SCCM: integración avanzada con SCCM y compliance.
- Patch My PC: parches populares en Windows de forma rápida.
- GFI LanGuard: escaneo de vulnerabilidades y parcheo.
- Red Hat Satellite / SUSE Manager / spacewalk: parcheo en distribuciones Linux.
- Ansible / Puppet / Chef: enfoque infraestructural como código (IaC).
- Nessus / Qualys / Rapid7: módulos de parcheo dentro de plataformas de seguridad.
- SolarWinds Patch Manager: combinación de escaneo y parcheo automatizado.
La elección depende del SO dominante, necesidad de cross-OS y recursos.
Diseño de políticas y calendarización
- a) Definición de cronograma
- Patch Tuesday (Microsoft): automatizar notificaciones y despliegue.
- Parches Linux: mensual (Red Hat y Debian) o según actualización.
- Parches de aplicaciones: a demanda para software crítico.
- b) Ventanas de mantenimiento
- Horarios fuera de producción o fines de semana.
- Duración definida y plazos de fallback.
- c) Fases piloto
- Comienza en entorno controlado con un pequeño número de sistemas.
- Validación con rollback automático si hay errores.
- d) Excepción autorizada
- Equipos aislados, hardware antiguo sin soporte.
- Documentar seguridad residual.
Fases del ciclo de vida del parche
- Detección: alertas WSUS, repositorios OS, módulos de seguridad MSS.
- Análisis: priorizar en función de riesgo/impacto negocio.
- Planificación: grupos segmentados de equipos.
- Prueba: validar en entorno real con rollback.
- Aprobación de cambio: tickets en ITSM, fechas de calendario.
- Despliegue automatizado: orquestación RPA, scripts idempotentes.
- Verificación: confirmación de versiones con repositorios.
- Remediación post-despliegue: logs, reinstalación si se detecta fallo.
- Reporte: KPIs de éxito, velocidad, cobertura.
- Feedback: retroalimentación a CSI y equipo.
Integración con ITSM y CMDB
La gestión de parches no es aislada:
- Cada ventana debe corresponder a Change requests.
- Integrar CI desde CMDB permite segmentación por criticidad.
- Post-parche lockstate asociado al CI.
- Notificaciones automáticas en ITSM.
- Incorporar acciones en CSI y auditorías.
Validación, pruebas y validación post-parche
Métodos de validación
- Hash o versión verificada.
- Sondeo remoto.
- Test funcional: servicios críticos, arranque, monitorización.
En caso de fallo
- Rollback automático o manual predefinido.
- Registro de root cause y ticket.
- Validación del entorno antes de re-intentar.
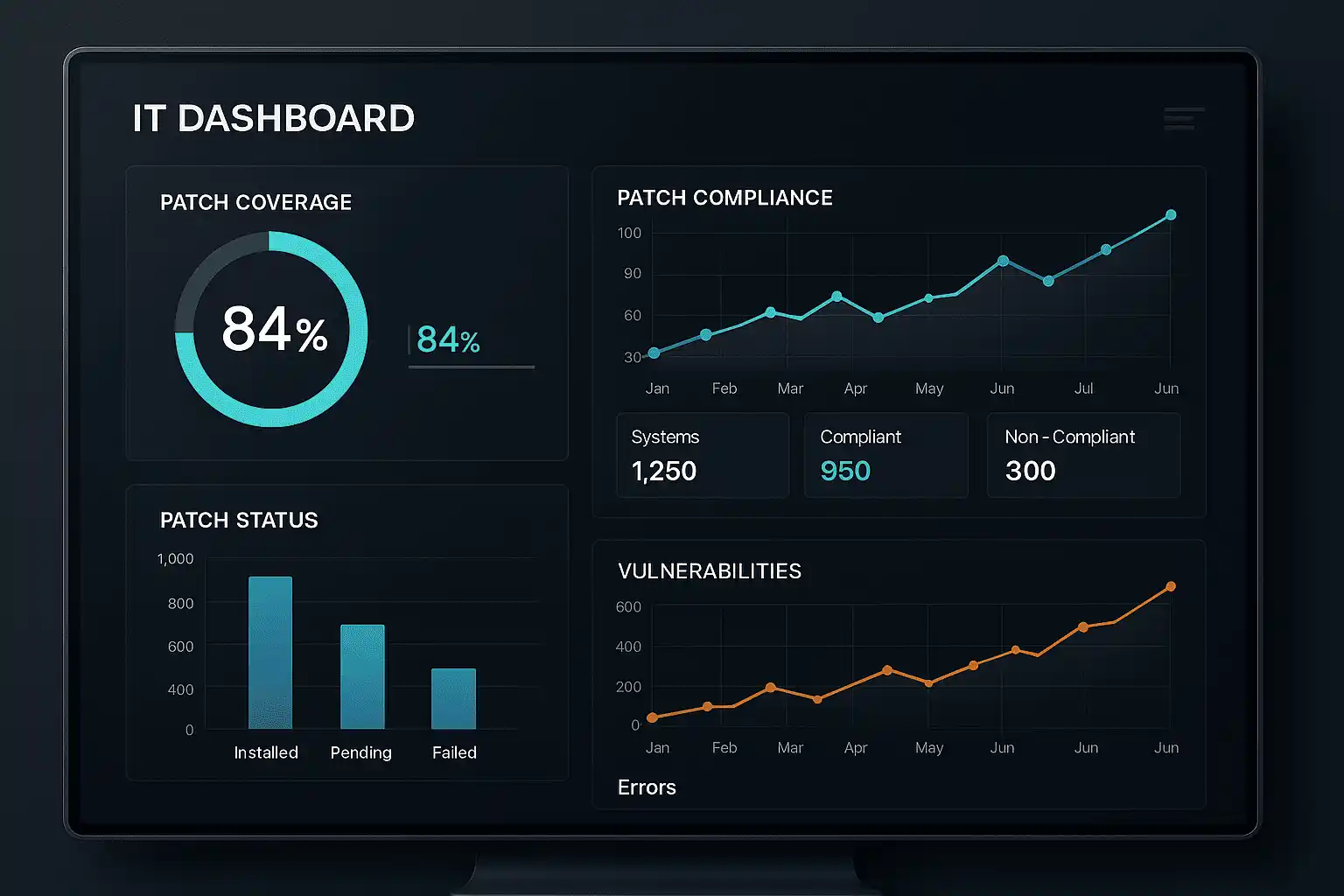
Indicadores (KPIs) para medir eficacia
- % de sistemas parcheados dentro de la ventana.
- % de éxito en instalaciones (sin rollback).
- Tiempo promedio de despliegue por parche.
- Frecuencia de fallos post-parche.
- Tiempo medio de reparación de errores (MTTR).
- Cobertura por sistema (por CI/entorno).
- Ventanas incumplidas por cambio manual.
- ROI: reducción de incidentes de vulnerabilidad detectados.
Retos frecuentes y recomendaciones
- Sistemas legacy sin soporte → Excluir con compensación técnica y monitoreo adicional.
- Ventanas de mantenimiento inadecuadas → Coordinar con stakeholders, aplicar pruebas de impacto.
- Errores post-instalación → Testing piloto robusto, rollback validado.
- Complejidad multi-SO y entornos heterogéneos → Uso de herramientas cross-plataforma (ManageEngine, Ansible).
- Cambio cultural → Formación, políticas claras y guías de uso.
- Riesgo de compliance → Verificación documentada, logs auditables y firma digital.
Plan de implementación paso a paso
- Definir alcance: inventario por entorno y criticidad.
- Seleccionar herramienta: según SO, recursos e integración.
- Diseñar política y calendario: stakeholder mapping.
- Construir laboratorio de pruebas piloto: parche de muestra.
- Implementar herramientas: configuración inicial, escaneo.
- Ejecutar piloto: equipo reducido en ventana controlada.
- Revisión piloto: ajustar, documentar lecciones.
- Despliegue extendido: producción, segmentado.
- Monitorización post-arranque: KPIs, validación.
- Governance y CSI: comité, auditorías, mejora continua.
Conclusión y próximos pasos
La gestión automatizada de parches es la columna vertebral de una estrategia de seguridad, operación y compliance. Bien diseñada, integrada con ITSM y ejecutada con rigor, aporta:
- Mayor resiliencia operativa.
- Mitigación de riesgos y cumplimiento normativo.
- Liberación de recursos técnicos.
- Cultura de mejora continua.
Próximos pasos:
- Auditar estado actual de parcheo.
- Definir política de gestión y calendario.
- Seleccionar la herramienta adecuada.
- Ejecutar piloto con entornos no críticos.
- Medir y ajustar con KPIs.