
- abril 13, 2026
- 0 Comments
- By Isidora

Miguel Ángel Tomé
Introducción: por qué la observabilidad es crítica en entornos cloud-native
El modelo cloud-native, basado en microservicios, contenedores y arquitecturas dinámicas, ha transformado la forma en que las organizaciones diseñan, despliegan y gestionan aplicaciones. A diferencia de las arquitecturas monolíticas tradicionales, donde todos los componentes están fuertemente acoplados, el modelo cloud-native permite:
- Escalabilidad horizontal automática, ajustando recursos según la demanda.
- Resiliencia, gracias a la redundancia y a la capacidad de aislar fallos por servicio.
- Flexibilidad, facilitando iteraciones rápidas y despliegues independientes.
- Adaptabilidad a entornos multinube, permitiendo balancear carga y optimizar costes.
Sin embargo, esta complejidad trae consigo nuevos retos operativos. Las herramientas tradicionales de monitoreo, que se centran en métricas básicas de infraestructura, no son suficientes para garantizar:
- Disponibilidad continua de servicios críticos.
- Rendimiento óptimo ante cargas variables y escenarios de alta concurrencia.
- Seguridad proactiva, detectando anomalías y ataques antes de que causen impacto.
- Cumplimiento de SLIs, SLOs y SLA, asegurando confiabilidad técnica y contractual.
La observabilidad es la práctica que permite comprender el comportamiento interno de sistemas complejos a través de la recolección, correlación y análisis de métricas, logs y trazas. Esto permite:
- Detectar problemas antes de que impacten al usuario final.
- Analizar causas raíz de fallos complejos en arquitecturas distribuidas.
- Optimizar recursos e infraestructura, reduciendo costes y aumentando eficiencia.
- Integrar seguridad y cumplimiento normativo en operaciones continuas.
Evolución de madurez de observabilidad cloud-native: de básico a predictivo
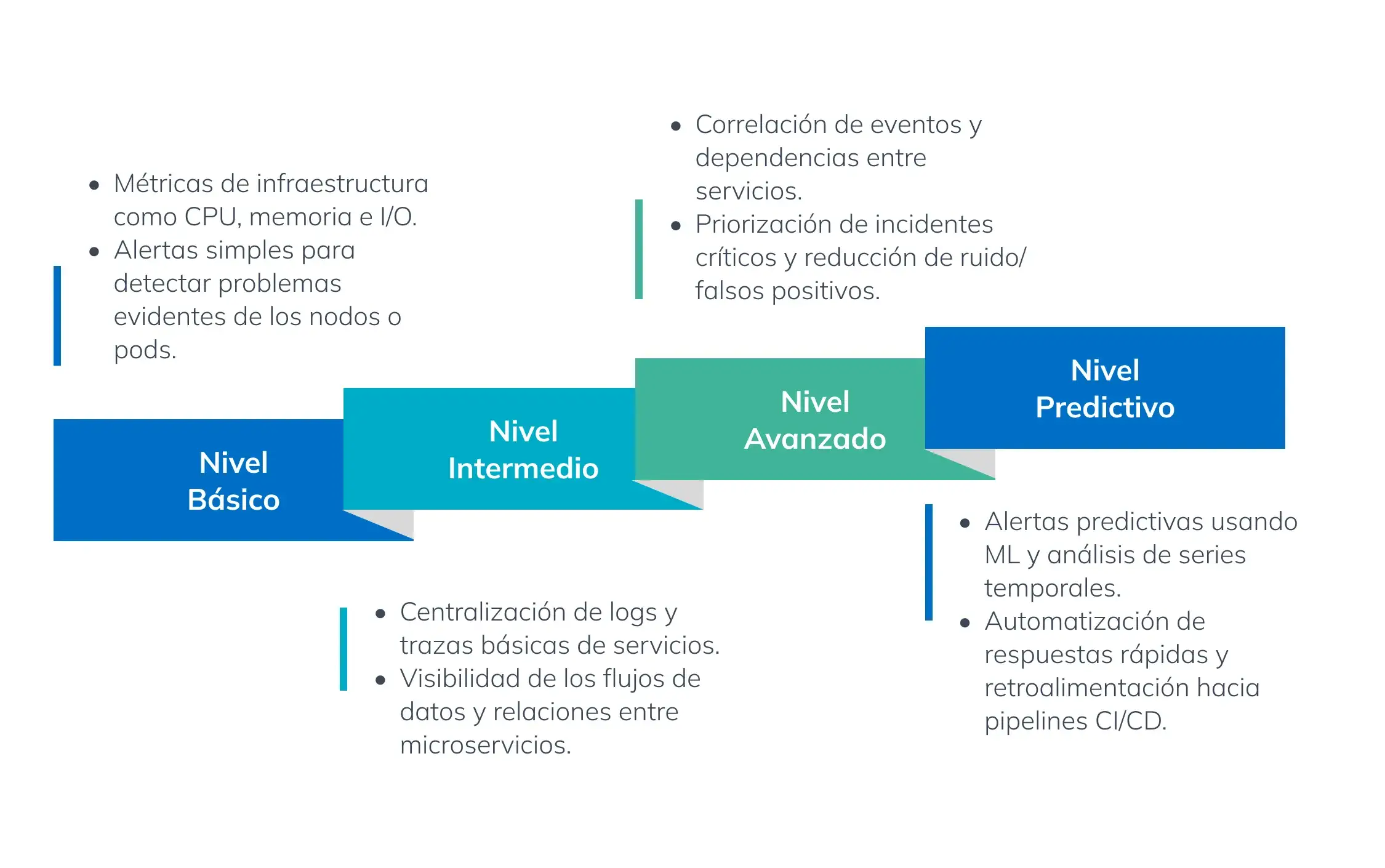
Fundamentos de observabilidad en entornos cloud-native
Diferencia entre monitoreo y observabilidad
Aspecto |
Monitoreo |
Observabilidad |
|---|---|---|
Datos |
Métricas predefinidas (CPU, memoria, I/O) |
Métricas, logs, trazas, eventos y contexto de servicio |
Alcance |
Infraestructura y componentes aislados |
Servicios completos, dependencias y transacciones distribuidas |
Propósito |
Detectar problemas conocidos |
Analizar problemas desconocidos y complejos |
Acción |
Alertas básicas |
Alertas inteligentes, correlación de eventos, diagnóstico predictivo |
En arquitecturas cloud-native, donde los microservicios se crean y destruyen dinámicamente, el monitoreo tradicional no ofrece visibilidad suficiente. La observabilidad permite entender comportamientos emergentes y proporciona un contexto completo sobre la relación entre servicios, flujos de datos y usuarios.
Principios fundamentales de observabilidad
- Telemetría completa
- Captura continua de métricas, trazas y logs en toda la infraestructura y aplicaciones.
- Incluye métricas del sistema operativo, contenedores, servicios y API externas.
- Contextualización de datos
- Uso de etiquetas consistentes: servicio, entorno, región, versión de aplicación.
- Permite filtrar y correlacionar eventos de manera precisa.
- Correlación de eventos
- Identificación de relaciones entre métricas y trazas de servicios dependientes.
- Facilita el análisis de fallos complejos que involucran múltiples microservicios.
- Alertas inteligentes y predictivas
- Reducción de falsos positivos mediante análisis estadístico y ML.
- Priorización de incidentes críticos y generación de alertas proactivas.
- Automatización y CI/CD integrado
- Validación de cambios en pipelines, incluyendo pruebas de resiliencia y SLIs.
- Despliegue de configuraciones de observabilidad como código, asegurando consistencia.
Flujo de integración de observabilidad: del desarrollo a producción
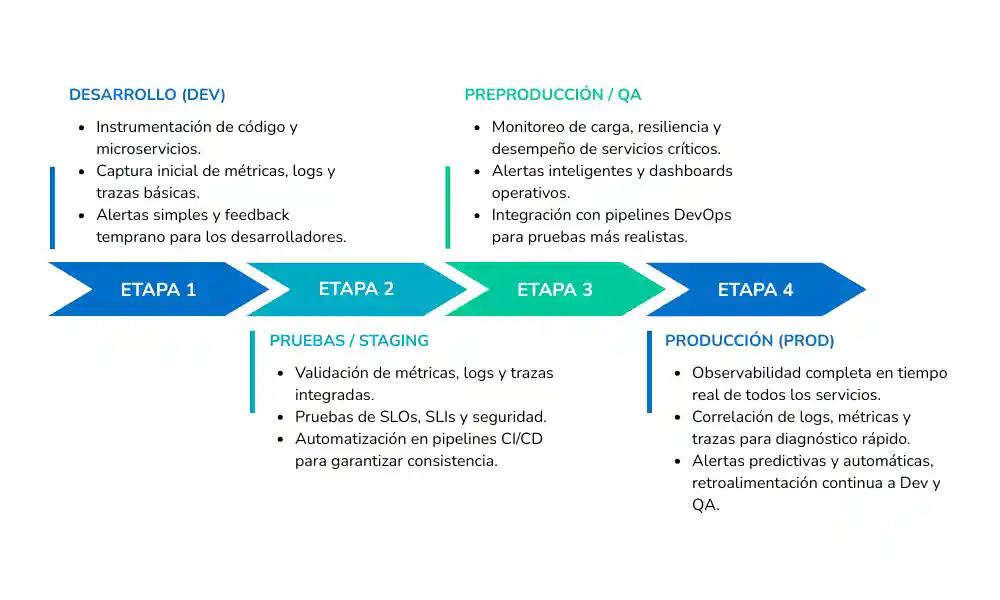
Arquitecturas modernas para observabilidad en Kubernetes y microservicios
Componentes clave de la arquitectura
- Agentes de recolección (Sidecar y DaemonSets)
- Prometheus Node Exporter: métricas de nodos y pods.
- cAdvisor: métricas de contenedores.
- OpenTelemetry Collector: agregación y exportación de trazas distribuidas.
- Logs centralizados
- Fluentd, Logstash o Loki: agregación y normalización de logs.
- Enriquecimiento con contexto de microservicios (request ID, usuario, región).
- Trazabilidad distribuida
- OpenTelemetry, Jaeger o Zipkin para rastreo de solicitudes entre servicios.
- Instrumentación manual y automática de aplicaciones.
- Almacenamiento y análisis
- TSDB (Prometheus, InfluxDB) para métricas temporales.
- Elasticsearch o ClickHouse para análisis de logs y trazas.
- Kafka o RabbitMQ para ingestión en tiempo real.
- Dashboards y visualización
- Grafana para paneles operativos y KPIs.
- Integración de métricas, logs y trazas para visión completa.
- Alertas inteligentes
- Basadas en anomalías y tendencias históricas.
- Correlación de múltiples eventos para priorizar incidentes.
- Integración con herramientas de gestión de incidentes (PagerDuty, Opsgenie, ServiceNow).
Arquitectura recomendada y patrones de implementación
- Sidecar pattern: cada contenedor incluye un agente de telemetría, asegurando visibilidad granular.
- Pipeline centralizado de telemetría: integración de logs, métricas y trazas en un repositorio unificado.
- CI/CD integrado con observabilidad: despliegue de microservicios y configuraciones de observabilidad como código.
- Seguridad y compliance: cifrado de datos en tránsito y en reposo, autenticación y control de acceso granular.
Métricas clave y alertas inteligentes
Métricas esenciales
Categoría |
Métricas críticas |
Descripción |
|---|---|---|
Infraestructura |
CPU, memoria, I/O, red, estado de nodos/pods |
Mide la salud física y virtual de los recursos |
Aplicación |
Latencia, throughput, tasa de errores, % éxito |
Evalúa rendimiento y experiencia de usuario |
Microservicios |
Comunicación entre servicios, colas, tiempos de procesamiento |
Detecta cuellos de botella y saturación |
Disponibilidad |
Uptime, SLIs, SLOs, SLA |
Garantiza cumplimiento de acuerdos de nivel de servicio |
Seguridad |
Accesos fallidos, autenticación, eventos de seguridad |
Identifica riesgos y ataques potenciales |
Alertas inteligentes y predictivas
- Anomalías estadísticas: desviaciones de métricas respecto a patrones históricos.
- Correlación de eventos: reducción de alertas redundantes y ruido.
- Alertas predictivas: predicción de fallos usando machine learning sobre series temporales.
- Automatización de respuesta: ejecución de scripts para mitigación rápida.
Integración con DevOps y DevSecOps
- Shift-left observability: instrumentación desde el desarrollo para detectar problemas antes del despliegue.
- Validación de cambios en CI/CD: pruebas de resiliencia, performance y cumplimiento de SLIs/SLOs.
- Feedback loop continuo: correlación de incidentes con cambios de código para mejora constante.
- Alertas de seguridad integradas: métricas y logs de seguridad dentro de pipelines DevSecOps.
Gobernanza, seguridad y compliance
- Control de accesos y RBAC: solo personal autorizado accede a métricas y logs críticos.
- Cifrado en tránsito y almacenamiento: protección de datos sensibles de telemetría.
- Trazabilidad completa: correlación entre despliegues, cambios de código y alertas.
- Cumplimiento normativo: auditoría de métricas y eventos para SOC2, ISO27001 y PCI-DSS.
Mejores prácticas avanzadas
- Definir SLIs, SLOs y SLA claros por microservicio.
- Centralizar los logs y estructurarlos con etiquetas consistentes.
- Implementar trazabilidad distribuida desde la solicitud inicial hasta el backend.
- Configurar alertas inteligentes con umbrales dinámicos y correlación de eventos.
- Automatizar dashboards y reporting con KPIs operativos y de negocio.
- Optimizar almacenamiento de métricas históricas y trazas para reducir costes.
- Capacitar equipos DevOps y SRE en análisis de métricas y resolución proactiva de incidentes.
Casos de uso avanzados
- Detección temprana de degradación de microservicios
- Correlación de latencia y errores en servicios críticos.
- Correlación de latencia y errores en servicios críticos.
- Prevención de incidentes en Kubernetes
- Métricas predictivas de CPU, memoria y estado de nodos para escalar automáticamente.
- Métricas predictivas de CPU, memoria y estado de nodos para escalar automáticamente.
- Optimización de recursos en entornos multinube
- Alertas inteligentes para balancear carga y reducir costes.
- Alertas inteligentes para balancear carga y reducir costes.
- Seguridad proactiva
- Monitoreo de accesos y eventos sospechosos en tiempo real.
- Monitoreo de accesos y eventos sospechosos en tiempo real.
- Auditoría de despliegues
- Correlación de cambios con métricas y alertas para trazabilidad y cumplimiento.
Arquitectura de referencia: observabilidad completa cloud-native
- Telemetría distribuida: métricas, logs y trazas de todos los componentes.
- Agentes sidecar y DaemonSets: Prometheus Exporter, OpenTelemetry Collector, Fluentd.
- Backend centralizado: TSDB, Elasticsearch y Kafka para ingestión masiva.
- Dashboards avanzados: Grafana y Kibana con alertas inteligentes.
- Automatización: pipelines CI/CD que despliegan microservicios y configuraciones de observabilidad como código.
Conclusión
La observabilidad en entornos cloud-native es un pilar estratégico que permite resiliencia, rendimiento y seguridad en arquitecturas modernas basadas en Kubernetes y microservicios. Con métricas inteligentes, trazabilidad distribuida y alertas predictivas, es posible:
- Detectar y resolver incidentes proactivamente.
- Reducir ruido y falsos positivos.
- Optimizar recursos y eficiencia operativa.
- Integrar observabilidad con DevOps/DevSecOps para un ciclo de retroalimentación continuo.
Una estrategia completa combina arquitectura robusta, métricas avanzadas, correlación de eventos, dashboards inteligentes y automatización, asegurando sistemas cloud-native confiables, escalables y auditables.

