
- mayo 11, 2026
- 0 Comments
- By Elena

Miguel Ángel Tomé
Introducción
En la última década, la arquitectura de software ha evolucionado hacia microservicios, contenedores y entornos cloud-native, permitiendo sistemas altamente escalables y modulares. Sin embargo, esta complejidad conlleva un desafío crítico: la resiliencia ante fallos. Los sistemas modernos dependen de múltiples servicios internos y externos, y cualquier interrupción puede propagarse de manera inesperada, generando incidentes difíciles de predecir y aislar.
El Chaos Engineering emerge como una disciplina para enfrentar este desafío, permitiendo probar la resiliencia de sistemas en condiciones reales. A diferencia de las pruebas tradicionales, que buscan verificar que todo funcione según lo esperado, el Chaos Engineering introduce fallos de manera controlada, evaluando cómo responde el sistema y cómo puede recuperarse automáticamente.
La práctica efectiva de Chaos Engineering requiere:
- Hipótesis claras sobre el comportamiento esperado de los servicios.
- Entornos controlados y replicables, similares a producción.
- Observabilidad avanzada, incluyendo métricas, trazas y logs.
- Automatización mediante pipelines CI/CD para validar la resiliencia de manera continua.
- Seguridad y gobernanza estrictas, garantizando cumplimiento y control.
Este artículo ofrece un análisis profundo de Chaos Engineering, cubriendo arquitecturas, métricas, patrones de experimentación avanzados, integración con DevOps/DevSecOps y mejores prácticas para aplicarlo sin riesgo en producción.
Principios Fundamentales de Chaos Engineering
Definición y objetivos
Chaos Engineering consiste en introducir perturbaciones deliberadas en sistemas distribuidos para evaluar su resiliencia ante fallos. No se trata de causar interrupciones arbitrarias, sino de identificar debilidades ocultas y validar mecanismos de recuperación automáticos y manuales.
Objetivos principales:
- Detección proactiva de fallos: Identificar vulnerabilidades antes de que causen incidentes reales.
- Validación de mecanismos de recuperación automática: Failover, retries, circuit breakers y fallback.
- Medición de resiliencia mediante métricas cuantificables: SLIs (Service Level Indicators), SLOs (Service Level Objectives) y MTTR (Mean Time to Recovery).
- Fortalecimiento de la cultura de resiliencia organizacional: Fomentar el aprendizaje de fallos y la mejora continua.
Diferencias con pruebas tradicionales
Característica |
Pruebas Tradicionales |
Chaos Engineering |
|---|---|---|
Propósito |
Verificar funcionalidad y rendimiento |
Evaluar resiliencia y tolerancia a fallos |
Escenarios |
Predecibles |
Impredecibles y controlados |
Riesgo |
Bajo en staging |
Controlado mediante límites y rollback automático |
Métricas |
Básicas, centradas en performance |
Complejas, combinando infraestructura, aplicación y resiliencia |
Alcance temporal |
Momentáneo |
Continuo, integrado en CI/CD |
Principios básicos de Chaos Engineering
- Hipótesis medibles: Cada experimento debe estar basado en una hipótesis que pueda verificarse cuantitativamente.
- Fallos graduales y controlados: Incrementar la intensidad de la perturbación de forma progresiva.
- Observabilidad integral: Métricas, trazas y logs deben correlacionarse para identificar causas raíz.
- Automatización y rollback seguro: Los experimentos deben detenerse automáticamente si se superan umbrales críticos.
- Iteración progresiva: Comenzar con servicios de menor criticidad antes de afectar producción.
Funcionamiento del Chaos Engineering controlado en sistemas cloud-native
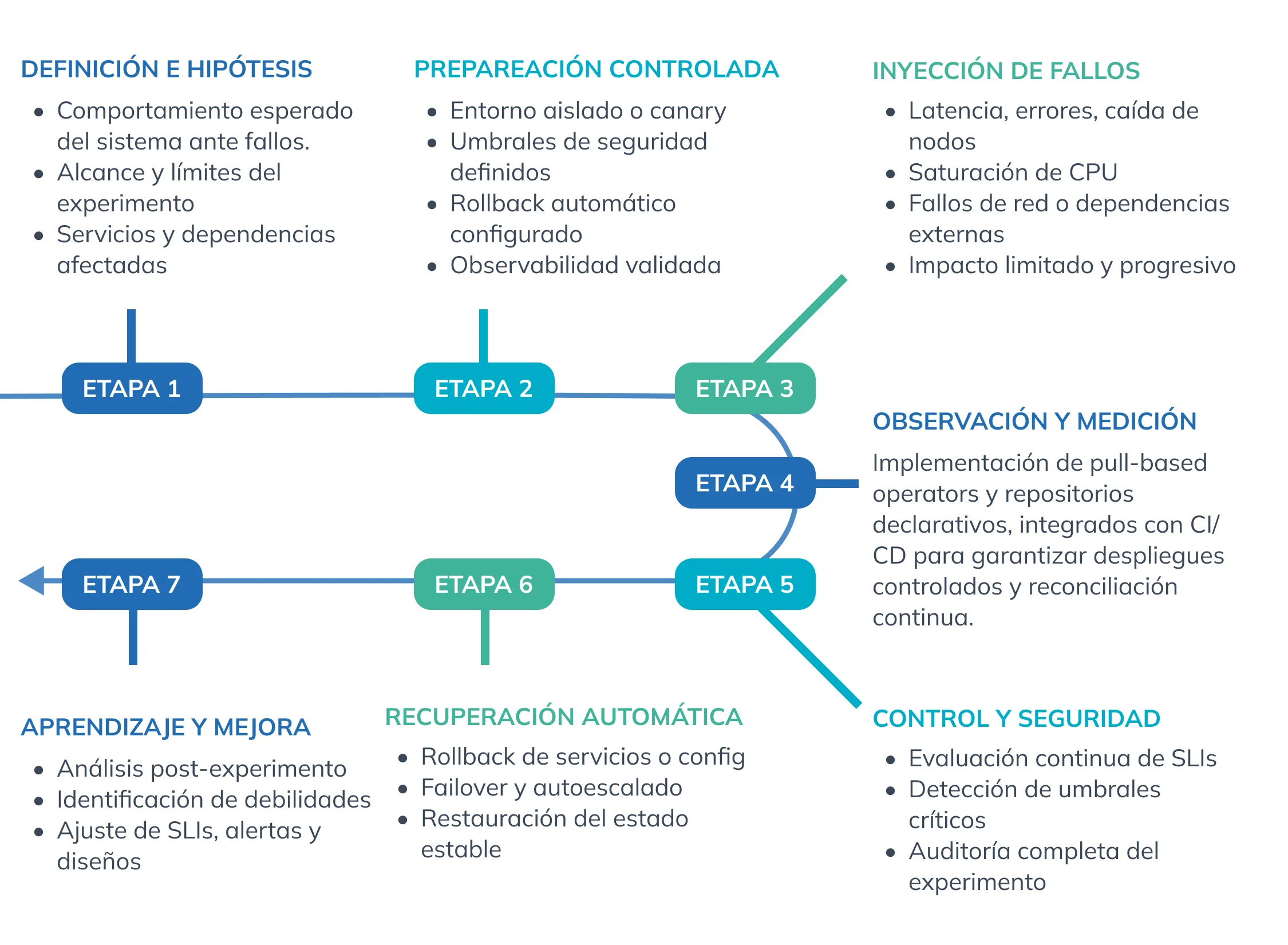
Arquitectura de Chaos Engineering Seguro
Para aplicar Chaos Engineering sin riesgo, se recomienda una arquitectura que aisle la experimentación y garantice observabilidad completa.
Componentes clave
- Entorno de experimentación controlado: Staging o entorno de sandbox replicando producción, con todas las dependencias críticas simuladas.
- Agentes de inyección de fallos: Deployables como sidecars o servicios que introducen latencia, errores de red, desconexiones o fallos en nodos de manera controlada.
- Observabilidad avanzada: Backend centralizado que integra métricas de infraestructura, logs y trazas de aplicaciones.
- Pipeline CI/CD resiliente: Integración de Chaos Engineering como paso automatizado para validar despliegues.
- Dashboard de análisis y alertas inteligentes: Correlación de métricas, detección de anomalías y alertas proactivas.
- Auditoría y gobernanza: Registro completo de todos los experimentos y resultados para aprendizaje organizacional y cumplimiento normativo.
Patrones de implementación
- Sidecar para fault injection: Agente desplegado junto al microservicio que simula fallos sin afectar otros servicios.
- Canary experiments: Aplicar fallos a un pequeño porcentaje de usuarios o nodos antes de ampliar el impacto.
- Fault-tolerant pipelines: Integración con pipelines CI/CD que permiten rollback automático si los SLIs no se cumplen.
- Segregación por criticidad: Diferenciar experimentos en servicios esenciales y no esenciales.
Métricas y Observabilidad en Chaos Engineering
La medición efectiva de la resiliencia requiere métricas de infraestructura, aplicación y resiliencia, así como trazabilidad detallada y alertas inteligentes.
Métricas de infraestructura
Permiten evaluar el estado físico y lógico del entorno donde se ejecutan los servicios.
- CPU, memoria, disco y I/O: identificar sobrecargas que podrían generar degradación de servicios. Por ejemplo, un nodo saturado puede disparar retries excesivos en microservicios dependientes.
- Saturación de red: medir latencia y throughput entre nodos y clústeres, fundamental en arquitecturas distribuidas y multinube.
- Disponibilidad de nodos y clústeres: seguimiento en tiempo real de la salud de Kubernetes, máquinas virtuales o instancias serverless.
- Latencia de comunicación interna: evaluar la eficiencia de servicios internos y colas de mensajes para detectar cuellos de botella antes de que afecten a usuarios finales.
Métricas de aplicación
Reflejan el comportamiento del software bajo estrés. En entornos cloud-native y microservicios, es crítico entender cómo las perturbaciones impactan en la experiencia del usuario y la integridad del negocio.
- Latencia de endpoints y throughput: medir el tiempo de respuesta de APIs y servicios críticos, detectando degradaciones incluso menores que podrían escalar.
- Tasa de errores y porcentaje de requests exitosas: evaluar el impacto de los fallos en la disponibilidad real de la aplicación.
- Saturación de colas y tiempos de respuesta de bases de datos: entender cómo los servicios internos y dependencias reaccionan ante carga incremental o fallos inducidos.
- Comportamiento de patrones resilientes: circuit breakers, retries, fallback y caching; estas métricas permiten validar que los mecanismos de mitigación funcionan como se espera.
Métricas de resiliencia
Miden la capacidad real del sistema para recuperarse y mantener la disponibilidad de servicios críticos.
- MTTR (Mean Time to Recovery): tiempo promedio de recuperación ante fallos inyectados. Crucial para evaluar la eficiencia de automatización y rollback.
- MTTF (Mean Time to Failure): tiempo promedio hasta la ocurrencia de un fallo; ayuda a dimensionar la criticidad de los servicios y priorizar mitigaciones.
- Disponibilidad efectiva de servicios críticos: porcentaje de tiempo que los servicios permanecen operativos durante experimentos de Chaos.
- Impacto en servicios dependientes: medir propagación de fallos para identificar cuellos de botella en la arquitectura de microservicios o dependencias externas.
Trazabilidad y logs
Esencial para entender cómo se comporta el sistema ante fallos y para auditoría de experimentos:
- Correlación de eventos de fallo con servicios afectados: relacionar incidentes en infraestructura con degradación de servicios.
- Registro de transacciones distribuidas: capturar el flujo completo de requests a través de microservicios, colas y bases de datos para análisis post-mortem.
- Integración con herramientas de trazas y logs distribuidos: OpenTelemetry, Jaeger, ELK Stack; permiten reconstruir la secuencia de eventos y evaluar el comportamiento real del sistema.
Alertas inteligentes
Las alertas en Chaos Engineering deben basarse en análisis contextual y correlación de métricas múltiples, no en thresholds simples:
- Basadas en anomalías y patrones históricos: detección de desviaciones inusuales en latencia, error o saturación de recursos.
- Correlación de métricas de distintos niveles: infraestructura + aplicación + resiliencia para priorizar incidentes críticos.
- Integración con sistemas de gestión de incidentes: PagerDuty, ServiceNow, Opsgenie; permite activar respuestas automáticas o alertas a equipos SRE/DevOps.
Técnicas de Chaos Engineering Controladas
Fault injection
El fault injection consiste en introducir fallos deliberados en componentes específicos del sistema, ya sea infraestructura, plataformas o aplicaciones, para observar la respuesta y recuperación del sistema.
Implementación avanzada:
- Tipos de fallos: latencia en llamadas a servicios, errores de red, desconexión de nodos, pérdida de paquetes o saturación de CPU/memoria en contenedores.
- Control granular: definir el porcentaje de usuarios, nodos o microservicios afectados para limitar el impacto. Por ejemplo, inyectar latencia solo en el 5% de las solicitudes a un servicio crítico permite evaluar resiliencia sin degradar toda la plataforma.
- Automatización: estos fallos se pueden introducir mediante sidecars, service meshes (como Istio o Linkerd), agentes de inyección o scripts de infraestructura. La automatización permite repetir experimentos y registrar métricas de forma consistente.
Medición de impacto:
- Latencia de respuesta del servicio afectado.
- Éxito de retries y fallback.
- Propagación del fallo a servicios dependientes.
- Métricas de negocio: porcentaje de transacciones exitosas y errores visibles para usuarios.
Experimentos de degradación progresiva
Esta técnica introduce fallos de manera incremental, permitiendo evaluar cómo el sistema maneja degradaciones leves antes de exponer fallos críticos. Es especialmente útil en sistemas de microservicios donde las dependencias entre servicios son complejas y los fallos pueden propagarse rápidamente.
Implementación avanzada:
- Iniciar con perturbaciones mínimas, como aumentar la latencia en una API interna o reducir la capacidad de un nodo de manera parcial.
- Incrementar gradualmente la intensidad del fallo (mayor porcentaje de usuarios afectados, saturación de CPU o memoria).
- Monitorear la efectividad de los mecanismos resilientes del sistema: circuit breakers, retries, caching, fallback, y autoescalado de pods en Kubernetes.
Beneficios:
- Identificar el punto exacto en el que los mecanismos resilientes dejan de ser efectivos.
- Validar la capacidad de degradación controlada sin impactar la experiencia del usuario final.
- Generar datos empíricos para ajustar SLIs/SLOs y alertas en producción.
Experimentos combinados avanzados
Los experimentos combinados representan el siguiente nivel de Chaos Engineering: introducir múltiples fallos simultáneos en nodos, microservicios y dependencias externas para evaluar resiliencia sistémica y propagación de errores.
Implementación avanzada:
- Simular caídas de nodos, latencia en servicios críticos y desconexión de APIs externas de manera coordinada.
- Configurar umbrales seguros de experimentación, con rollback automático si se supera un impacto definido en métricas críticas.
- Integrar observabilidad avanzada: dashboards que correlacionen logs, trazas y métricas de todos los servicios involucrados.
Beneficios:
- Identificar dependencias ocultas o puntos de fallo críticos.
- Ajustar estrategias de mitigación automática y alertas proactivas.
- Preparar al equipo DevOps/SRE para escenarios de fallo reales en producción multinube.
Integración con DevOps y DevSecOps
Pipelines CI/CD resilientes
- Automatización de experimentos como parte del pipeline de despliegue.
- Validación de SLIs y SLOs antes de promover código a producción.
- Rollback automático ante violación de métricas críticas.
Observabilidad integrada
- Métricas, logs y trazas desde desarrollo hasta producción.
- Alertas inteligentes integradas en pipelines para feedback inmediato.
Seguridad y compliance
- Asegurar que los experimentos no afecten datos sensibles.
- Control de acceso granular y registro completo para auditoría.
Mejores Prácticas Avanzadas
- Definir SLIs/SLOs por microservicio y nivel de criticidad.
- Iterar experimentos comenzando en servicios menos críticos.
- Monitorear métricas en tiempo real con alertas configurables.
- Automatizar rollback y mitigación ante fallos críticos.
- Registrar todos los experimentos para análisis y aprendizaje.
- Aplicar Machine Learning para detectar patrones y predecir fallos.
- Fomentar una cultura de resiliencia en equipos DevOps/SRE.
Casos de Uso Avanzados
- Fallos en clústeres Kubernetes: Validar reequilibrio de pods, escalabilidad automática y tolerancia a nodos caídos.
- Bases de datos distribuidas: Simular fallos en réplicas y failover automático.
- Dependencias externas críticas: Desconexión controlada de APIs y colas de mensajes.
- Microservicios esenciales: Degradación gradual para probar patrones de fallback.
- Entornos multinube y multi-región: Validar resiliencia ante fallos de proveedor o región.
Conclusión
Aplicar Chaos Engineering sin riesgo permite:
- Detectar vulnerabilidades ocultas en sistemas distribuidos y microservicios.
- Garantizar resiliencia y recuperación ante fallos reales.
- Integrar prácticas avanzadas de DevOps y DevSecOps.
- Fortalecer la cultura organizacional orientada a confiabilidad y observabilidad.
El éxito radica en la experimentación controlada, observabilidad avanzada, integración con pipelines y auditoría continua, convirtiendo Chaos Engineering en un pilar estratégico de resiliencia para entornos cloud-native.




